Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications.
We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an ‘observation’ window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV’s potential for practical applications. Our code is available at https://github.com/FasterDecoding/SnapKV.
Many inspiring works have successfully expanded LLMs to handle longer contexts, overcoming the difficulties in context maintenance and attention mechanism scalability, such as GPT-4 [1] and Command-R [2] with context length 128K, Claude-3 [3] with 200K, and Gemini-Pro-1.5 with 1M [4]. Despite their impressive capabilities, LLMs still face significant challenges when dealing with long context inputs. Specifically, the KV caches in attention calculation become an obstacle in efficiently processing long context. During inference time, as input length increases, the decoding speed per step grows linearly due to the computation for attention across past KVs. Moreover, the large KV cache created during prompting requires significant on-chip and off-chip memory, increasing hardware demands and limiting model scalability.
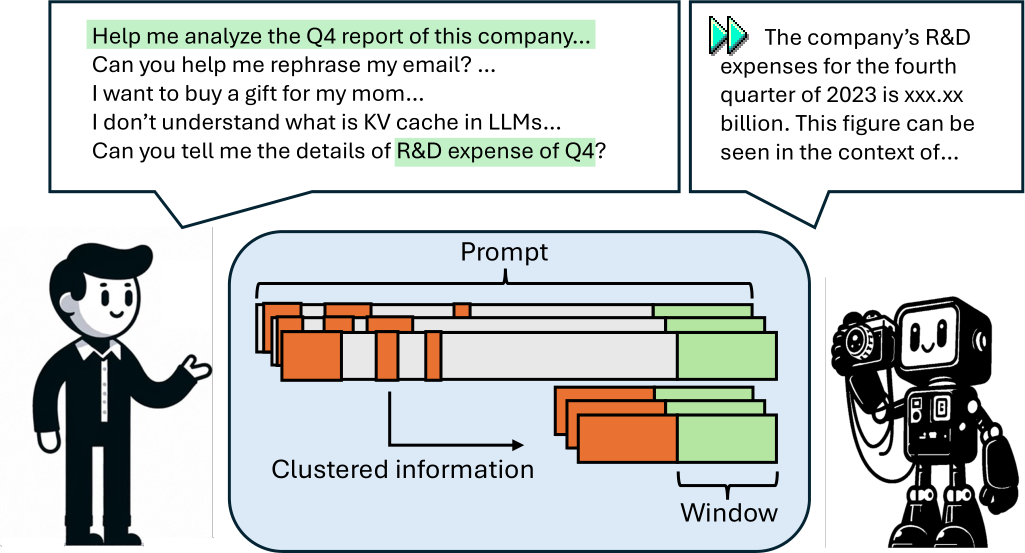
Figure 1: The graph shows the simplified workflow of SnapKV, where the orange area represents the group of positions per head clustered and selected by SnapKV. These clustered features are then used to form a new Key-Value pair concatenated with the tokens in the observation window (denoted as ‘Window’). Together, the selected prefix and observation windows constitute the new KV cache utilized for the generation.
There are many perspectives to mitigate these problems, including KV cache eviction during token generation [5–8]. However, most of these methods lack a detailed evaluation of the generated context in a long-context setting. Moreover, they mainly focus on optimizing the KV cache appended during generation steps, while overlooking the realistic problem of compressing KV cache for input sequences, which is typically the bottleneck in memory efficiency. In practical applications such as chatbots and agents, where inputs can be multi-turn conversations, extensive articles or codebases [1, 9, 10], input sizes are often much larger than the sizes of generated responses, resulting in significant overhead. Additional challenge lies in compressing such vast inputs without losing crucial information for accurate generation, especially in scenarios with various noisy contexts.
In our paper, we identify the patterns of these important prompt attention features during generation. To validate the robustness of this finding, we also design a thorough set of experiments across diverse inputs in terms of length, format, and content. Based on our observations, we derive an innovative and intuitive method, SnapKV, which can effectively compress the KV cache for long sequence inputs without compromising the model’s accuracy. Our contributions are as follows:
• We design experiments to explore the patterns of attention features in output generation, focusing on three key questions:
![]()
2. How does the context and instruction positioning influence this attention allocation pattern?
3. Does the nature of the user’s instructions play a role in shaping these attention patterns?
Our finding suggests that most of the LLMs’ attention allocation of input sequence remains unchanged during generation. Thus, LLMs knows what you are looking for before generation.
• We develop an efficient algorithm, SnapKV, inspired and validated by extensive observations and testing. SnapKV intelligently identifies important KVs with minimal modification (See Fig. 1). The algorithm can be easily integrated into popular deep-learning frameworks with just a few code adjustments.
• We evaluate SnapKV for accuracy and efficiency across diverse LLMs and long-sequence datasets, affirming its improvement over previous work and comparability to conventional KV caching. Furthermore, we conduct the Needle-in-a-Haystack test to demonstrate its memory efficiency and illustrate decoding speed enhancements through varied batch sizes and input lengths. In addition, SnapKV’s integration with a leading RAG model showcases its
extended performance capabilities. We also show that SnapKV can be combined orthogonally with other acceleration strategies such as parallel decoding.
Many previous works address the KV cache compression by evicting the KV cache using different algorithms. For example, StreamLLM [5] maintains the first few tokens and the local tokens to effectively reduce the KV cache size. However, it faces the challenge of losing important information since it continuously evicts the KV cache.2 Another perspective is to compress the KV cache for generation steps. Heavy-Hitter Oracle [6] introduces a KV cache eviction policy that greedily selects tokens during generation steps based on a scoring function derived from cumulative attention. While this approach effectively compresses the KV cache for generated tokens, it overlooks compression of the input sequence KV cache, which is crucial for reducing memory and computational overhead. Building on a similar concept, Adaptive KV Compression (FastGen) [8] implements a dual-phase algorithm that encompasses four KV cache compression policies. Initially, it identifies optimal policies through profiling results obtained from prompt encoding. Subsequently, it dynamically evicts caches during the generation phase based on these policies. Nonetheless, it faces the similar problem with H2O. ScissorHands [7] focuses on identifying and retaining pivotal tokens that exhibit a consistent attention weight pattern with previous token windows during generation steps. However, this method concentrates solely on the window of previous pivotal tokens in generation and neglects the extensive input that contains essential information for generating accurate responses. This oversight could lead to an inability to extract detailed information from prompts.
In summary, existing compression methods merely address the challenges encountered in real-world applications, such as document processing and multi-round chats, where prompts are exceptionally long yet require accurate information retrieval. In common use cases, the generated outputs, like summaries, code pieces, or retrieved data, are significantly shorter compared to the extensive input sequences from novels, entire code bases, or annual financial reports. Although these techniques may effectively reduce the KV cache size during the generation phase, they do not tackle the primary overhead and challenges arising from a lack of comprehension of complex input contexts, thus leaving the critical issues unresolved.
In this section, we present our observations regarding the patterns in the Query-Key matrix during token generation. We discuss how these patterns can be potentially exploited for KV cache compression. Our findings are based on the analysis of various generation contexts and the behavior of attention mechanisms in LLMs and are concluded into three key observations as follows:
1. Pattern consistency across contexts: Irrespective of the generation context length, we observed that specific keys within the prompt consistently exhibit higher attention weights. Such “active” keys tend to follow stable patterns that appear to be intrinsically related to the structure and content of the prompt. (Sec. 3.1)
2. Invariance to question positions in summarization tasks: In the context of long summarization and question-answering tasks, the positioning of questions within the prompt (either at the beginning or the end) does not significantly alter the consistency of attention patterns observed. This suggests a level of robustness in how we can obtain the attention of relevant features trivially, regardless of the position of questions. (Sec. 3.2.1)
3. Contextual dependency of patterns: The observed attention patterns are highly contextsensitive, indicating a strong association with the specific instructions posed by the user
(Sec. 3.2.2). Thus, a context-aware KV compression approach can potentially lead to better performance.
To structure our experimental analysis coherently, we introduce the following terminologies:
Prompt Length (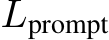 ): The total length of the user-provided input. Prefix Length (
): The total length of the user-provided input. Prefix Length (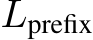 ): The length of the input preceding the observation window. It is part of the prompt and does not include the observation window. Observation Window (
): The length of the input preceding the observation window. It is part of the prompt and does not include the observation window. Observation Window (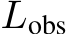 ): The last segment of the prompt. This window is crucial for analyzing the influence of different contexts on attention patterns. These definitions are interconnected as follows:
): The last segment of the prompt. This window is crucial for analyzing the influence of different contexts on attention patterns. These definitions are interconnected as follows:
![]()
Voting: The process of calculating attention weights for each query within the observation window across all heads, aggregating these weights to highlight the prefix positions that are considered most significant.
For a single batch of sequence, formally:

where Top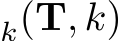 selects the indices of the top k values in tensor T per head, k is defined as
selects the indices of the top k values in tensor T per head, k is defined as 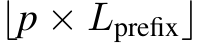 . The tensor
. The tensor 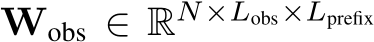 represents the subset of the prompt softmaxnormalized attention features over N heads.
represents the subset of the prompt softmaxnormalized attention features over N heads.
Hit Rate: The hit rate, H, quantifies the effectiveness of the voting mechanism by measuring the ratio of attention features identified as significant by the voting process that are also essential in the generation outcome, calculated as:
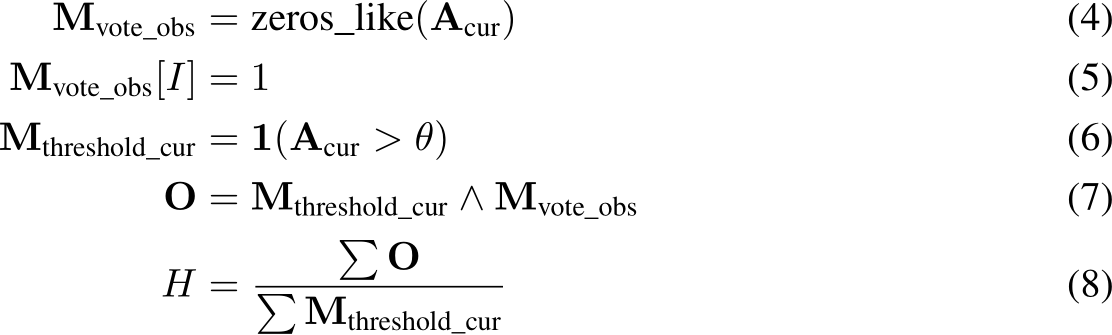
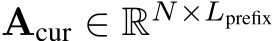 represents the attention features between the current generated query and prefix keys. The threshold operation filters
represents the attention features between the current generated query and prefix keys. The threshold operation filters 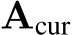 to retain only values exceeding
to retain only values exceeding ![]() , indicating significant attention activations. The overlap O between these significant activations and the mask M quantifies the alignment of the current attention with previously identified significant features. The hit rate H is then computed as the ratio of the sum of overlap O to the sum of significant activations
, indicating significant attention activations. The overlap O between these significant activations and the mask M quantifies the alignment of the current attention with previously identified significant features. The hit rate H is then computed as the ratio of the sum of overlap O to the sum of significant activations 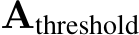 , providing a metric for the efficacy of the attention mechanism in recognizing and emphasizing important attention features within the context. We can use H(Mthreshold_cur
, providing a metric for the efficacy of the attention mechanism in recognizing and emphasizing important attention features within the context. We can use H(Mthreshold_cur![]() denote combination of eq. 7 and eq. 8. We use p = 0.05 (top 5% location per head) and
denote combination of eq. 7 and eq. 8. We use p = 0.05 (top 5% location per head) and ![]() (note it is a large value due to the softmax function over a long sequence) for the observation experiments. The model we probe is Mistral-7B-Instruct-v0.2.
(note it is a large value due to the softmax function over a long sequence) for the observation experiments. The model we probe is Mistral-7B-Instruct-v0.2.
3.1 Observations in Multi-Turn Conversations
This study examines if the positions of features identified as crucial in the observation window maintain their significance in the subsequent token generation. The analysis utilizes samples from
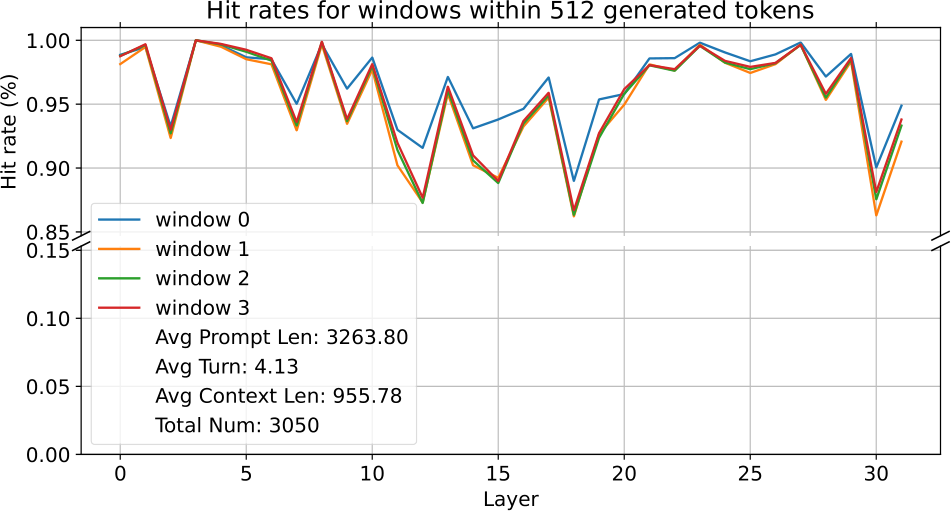
Figure 2: The layer-wise average hit rate of important positions utilized along token generation with an average input length exceeding 3k.
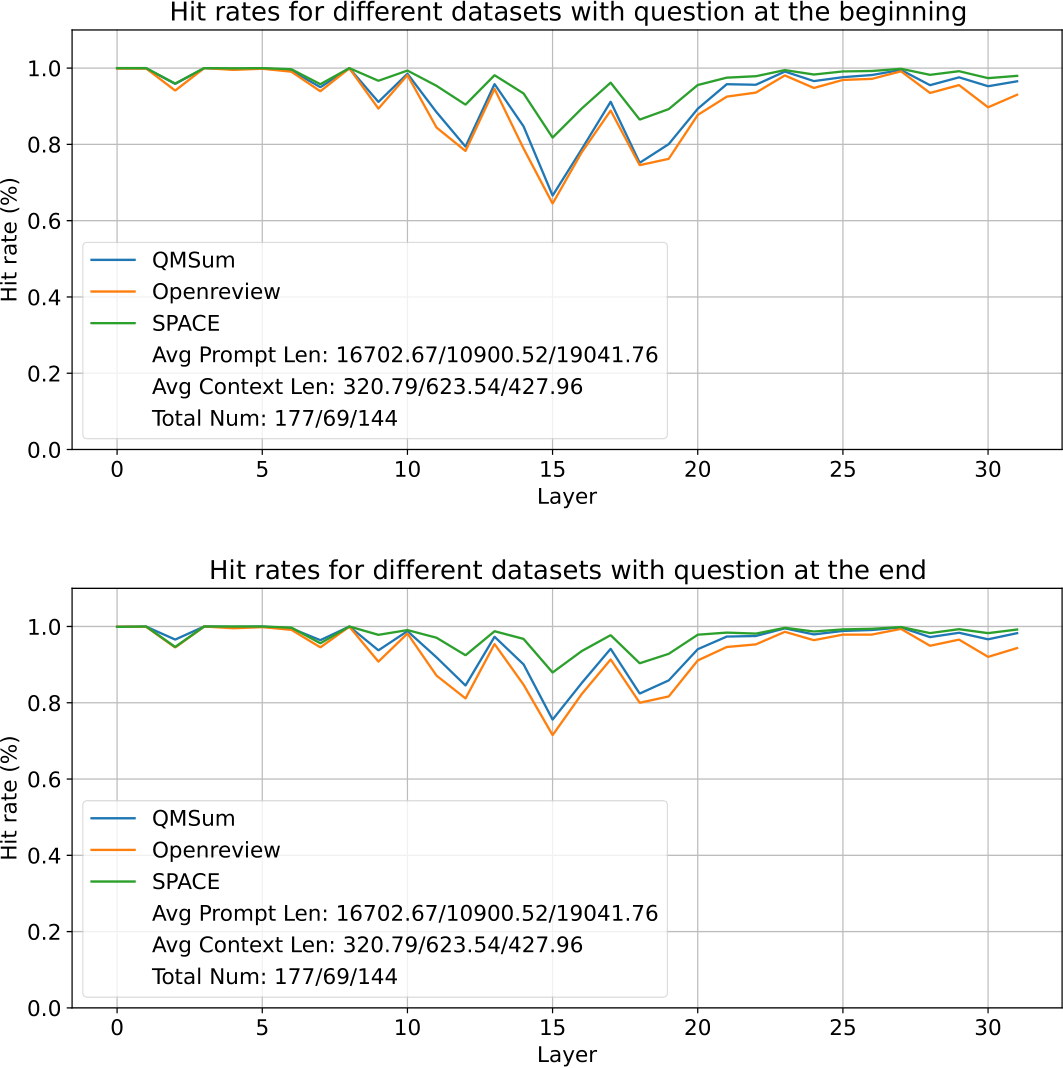
Figure 3: The layer-wise average hit rate of important positions utilized by prompts with questions at the beginning and the end.
Ultrachat [11], a multi-turns, high-quality instruction dataset consisting of 1.4 million dialogues. We further filter the sequences with response length greater than 512 and prompt length greater than 3k. In the experiment, we split the generated tokens into 4 context windows, each spanning 128 tokens, to compute the averaged hit rates of these windows versus the observation window with size 32. According to the findings presented in Fig.2, important keys in prefixes obtained from voting in observation windows exhibit remarkable consistency throughout the generation process, as evidenced by high hit rates.
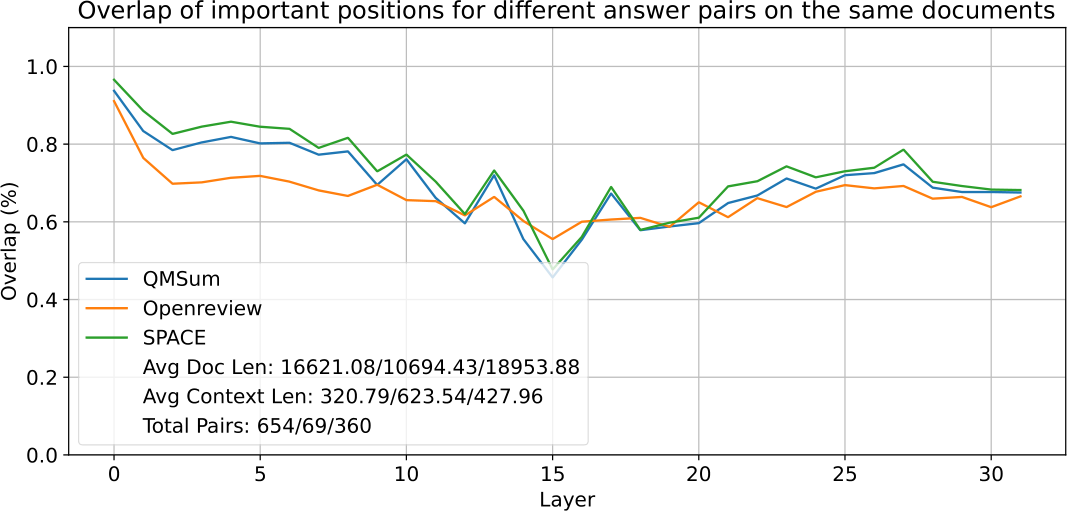
Figure 4: The layer-wise overlap of important positions utilized by different question-answer pairs in the same dataset.
3.2 Observations in Long Document QA
To further validate this finding, we also observe on multiple long documents QA datasets including QMSum [12], a query-based multi-domain meeting summarization; Openreview [13], a collection of papers from openreview.net; SPACE [14], an extractive opinion summarization in quantized transformer spaces.
3.2.1 Effectiveness of Instruction Positions
Our investigation also extends to the significance of instruction positioning on the interpretability of LLMs and their selection of important features. We calculate the average hit rate for the responses using the same observation window size of 32 as in the previous experiment. Our results shown in Fig. 3 indicate that across all three datasets, the hit rates are consistently high regardless of whether instructions are positioned before or after extensive supplementary contexts. This consistency suggests that the patterns identified by observation windows are independent of the question’s positions.
3.2.2 Effectiveness of Various Instructions for One Document
Furthermore, we investigate whether instructions will affect the selection of important features even if the provided context is the same. Our experiment utilizes different instructions on the same document and selects the important features based on the observation window that consists of both the instructions and their corresponding responses. Then we calculate the hit rates between important features selected by different instruction-response pairs within the same document by using ![]() . By varying the instructions, we observe that different instructions prioritize different prefix keys, as indicated by the descending trend in hit rates shown in Fig. 4.
. By varying the instructions, we observe that different instructions prioritize different prefix keys, as indicated by the descending trend in hit rates shown in Fig. 4.
Our findings reveal an interesting aspect of KV cache management in LLMs: the important attention features change with different instructions. This variability challenges the effectiveness of static compression methods that depend on constant weighted importance or fixed policies [7, 6, 8]. Thus, the complex relationship between context and related KV cache emphasizes the need for context-aware compression strategies and highlights the limitations of current methods that ignore this dynamic.
4.1 Basic Method
In the attention mechanism, keys and values are tensors containing information from the previous context. The linear growth in prompts will lead to exponential time complexity for generation due to the Query-Key matrix multiplication. SnapKV addresses this by keeping prompt KV cache counts constant during generation, significantly reducing serving times for long-context LLMs.
The fundamental approach of SnapKV involves identifying and selecting the most crucial attention features per head to create the new KV cache. SnapKV operates through two stages as shown in Fig. 1:
• Voting for Important Previous Features By the voting process defined previously (Eq. 1), we select the important features based on the observation window—defined as the last segment of the prompt. Sec. 3.1 highlights the consistency of these attention features throughout the sequence, suggesting that these features are vital for subsequent generation. Besides, we implement clustering to retain the features surrounding the selected features (See Sec.4.2).
• Update and Store Truncated Key and Value We concatenate these selected features with the window features, which encompass all features containing prompt information. We store back the concatenated KV caches for later use in generation and save the memory usage.

4.2 Efficient Clustering via Pooling
In LLMs, information retrieval and generation rely on features with high attention weight and are supplemented by copying the rest in context using induction heads [15]. Hence, naively selecting the top features results in retaining only portions of details and then losing the completeness of the information. For example, such compression might cause the LLMs to retrieve only the country code of a phone number and hallucinate the rest. Our experiment also revealed that only selecting the features with the highest weights is insufficient (Sec. 5.2). Such sparse selection risks compromising the contextual integrity encapsulated in between features, thereby reducing accuracy. Based on the insights, We propose a fine-grained clustering algorithm utilizing a pooling layer shown in Line 14.
In our experimental setup, we explore the performance of SnapKV across models that can handle extended sequence contexts. First, we deliver a pressure test and benchmark the speed of LWM-Text-Chat-1M [16], which is state-of-the-art regarding its context length. We then conduct an ablation study on Mistral-7B-Instruct-v0.2 to understand the influence of pooling on the model’s information retrieval performance. We assess model performances using the LongBench [17] dataset. Further, we dive into a comprehensive examination of the Command-R [2] model, another leading open-source model in the field. Lastly, we show that SnapKV can be utilized with other acceleration strategies such as parallel decoding.
5.1 Benchmarks on LWM-Text-Chat-1M
LWM-Text-Chat-1M [16] is a 7B instruction-finetuned model with up to one million context length. In this section, we conduct a pressure test on this model and examine its algorithmic efficiencies through the lens of hardware optimization.
5.1.1 Needle-in-a-Haystack
The Needle-in-a-Haystack test [18] challenges the model to accurately retrieve information from a specific sentence("needle") hidden within a lengthy document (the "haystack"), with the sentence placed at a random location. To rigorously evaluate SnapKV’s capabilities, we extended the document length to 380k tokens which is the longest content that can be processed by a single A100-80GB GPU. We configured the prompt KV cache size to 1024, enabling SnapKV to select the most crucial 1024 attention features from the prompt using our algorithm for answer generation, with a maximum pooling kernel size of 5 and a observation window size of 16. The compelling outcomes in Fig. 5 from the Needle-in-a-Haystack test underscore SnapKV’s potential to precisely manage small details on extremely long input contexts with a 380x compression ratio.
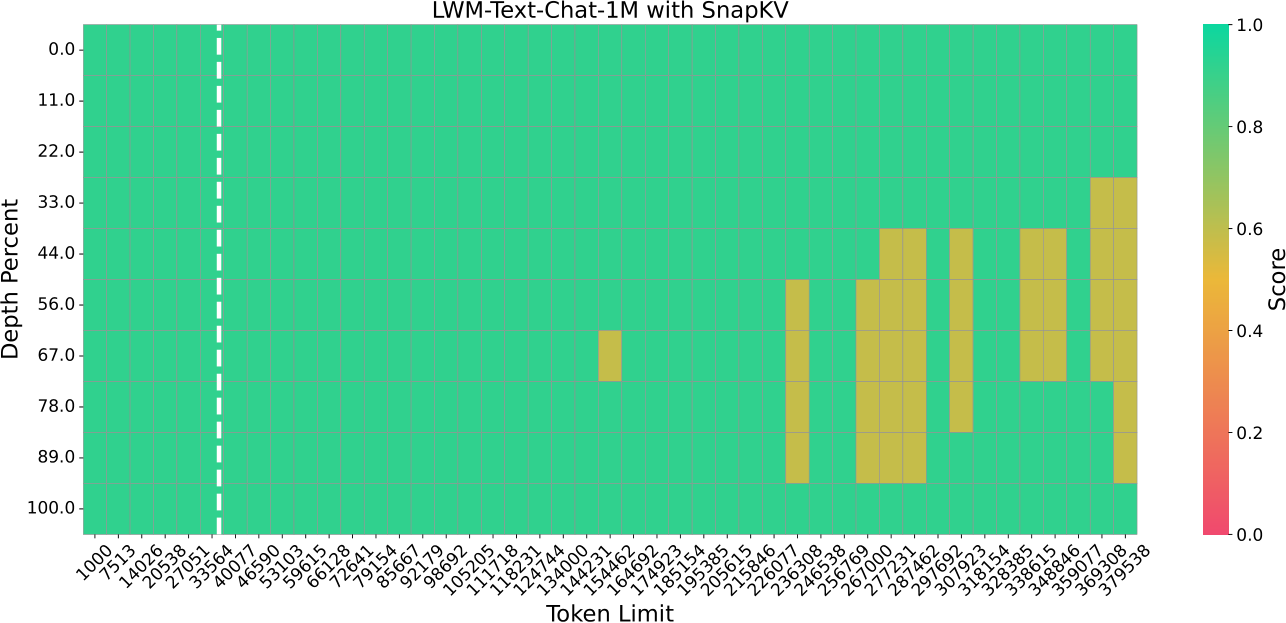
Figure 5: Needle-in-a-Haystack test performance comparison on single A100-80GB GPU, native HuggingFace implementation with only a few lines of code changed. The x-axis denotes the length of the document (the “haystack”); the y-axis indicates the position that the “needle” (a short sentence) is located within the document, from 1K to 380K tokens. For example, 50% indicates that the needle is placed in the middle of the document. Here LWMChat with SnapKV is able to retrieve the needle correctly before 160k and with only a little accuracy drop after. Meanwhile, the original implementation encounters OOM error with 33k input tokens.
5.1.2 Decoding Speed and Memory Bound
We further benchmark the speed of LWM-Text-Chat-1M under different batch-size settings using SnapKV. We set the maximum prompt KV cache size as 2048 for SnapKV. There are two main
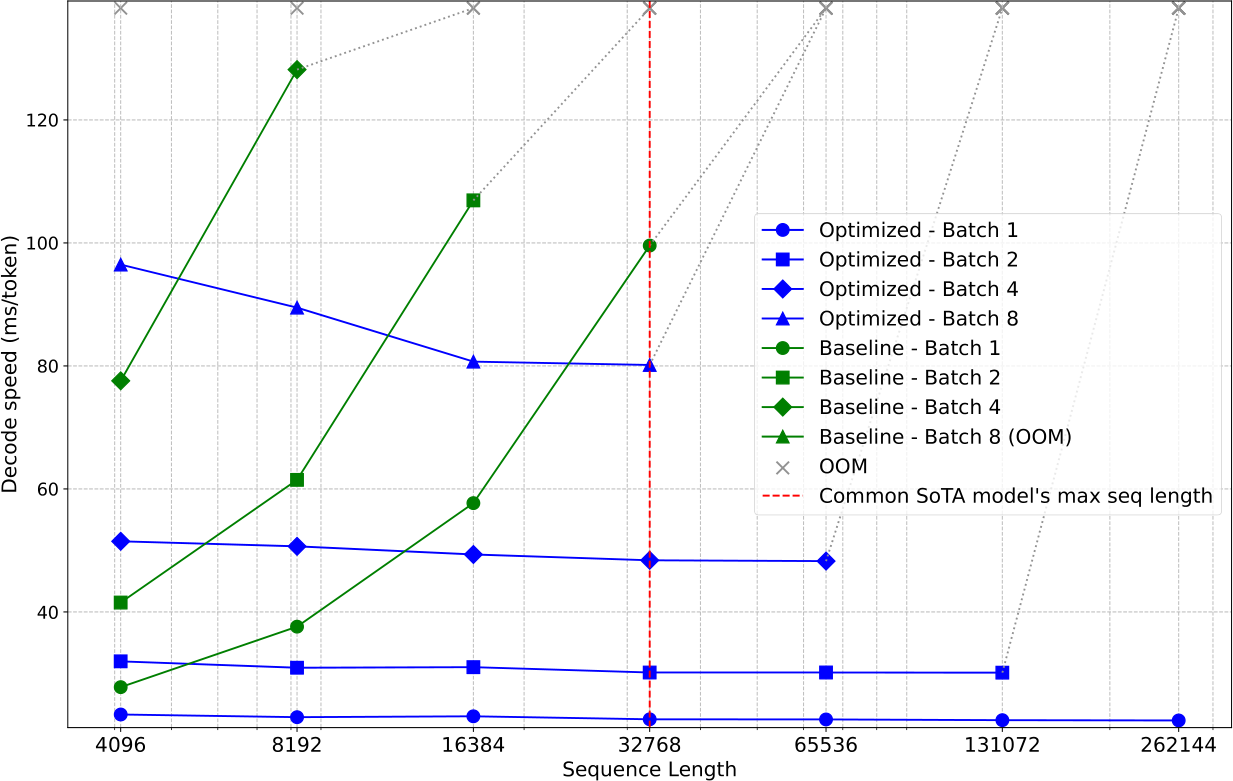
Figure 6: Deconding speed comparison of baseline implementation and SnapKV optimized solutions on various batch sizes. The x-axis denotes the input sequence length; the y-axis indicates decoding speed (ms/token). All experiments are conducted on an A100 80GB GPU. The red dotted line denotes the current state-of-the-art open-sourced models’ context length.
takeaways from our experiment on decoding speed and input sequence length on various batch sizes, as shown in Fig. 6. First, as the input sequence length increases, the decoding speed of the baseline implementation escalates exponentially. Conversely, the SnapKV-optimized model maintains a constant decoding speed since the KV cache stays the same and there is no extra update during the inference. For instance, at a sequence length of 16k and a batch size of 2, the decoding time for the baseline model surpasses 0.1 seconds, whereas the SnapKV-optimized model consistently remains below 0.04 seconds, achieving approximately a 3.6x speedup. Second, with the same batch size, the model optimized with SnapKV can decode significantly longer sequences. For example, at a batch size of 2, the baseline model encounters an OOM issue beyond 16k input tokens, whereas the SnapKV-enhanced model extends this limit to 131k input tokens, indicating an approximately 8.2x improvement. This demonstrates SnapKV’s effectiveness in minimizing memory consumption.
5.2 Ablation Study of Effectiveness of Pooling
We perform an ablation study to assess the impact of our pooling technique, a straightforward but efficient method for consolidating information through clustering. Our evaluation utilizes the modified LongEval-Lines benchmark [19], incorporating random generated pairs and averaged scores. LongEval-Lines presents a greater challenge compared to Needle-in-a-Haystack because it involves identifying key-value pairs in noisy contexts of the same format, while in Needle-in-a-Haystack, the relevant information is more distinctly separated from other contexts. We apply max pooling with a kernel size of 5 and use the observation window with a size of 16. The findings, illustrated in our results (Fig. 7), indicate that pooling significantly enhances retrieval accuracy compared to methods not utilizing pooling. We hypothesize that this is due to the ability of strong attention mechanisms to focus on the initial portion of tokens. Without information compression, large language models tend to replicate the subsequent tokens, leading to retrieved partially correct results when the KV cache is compressed as we observed. Note that throughout our experiments, the choice between max pooling and average pooling did not yield significant differences in performance.
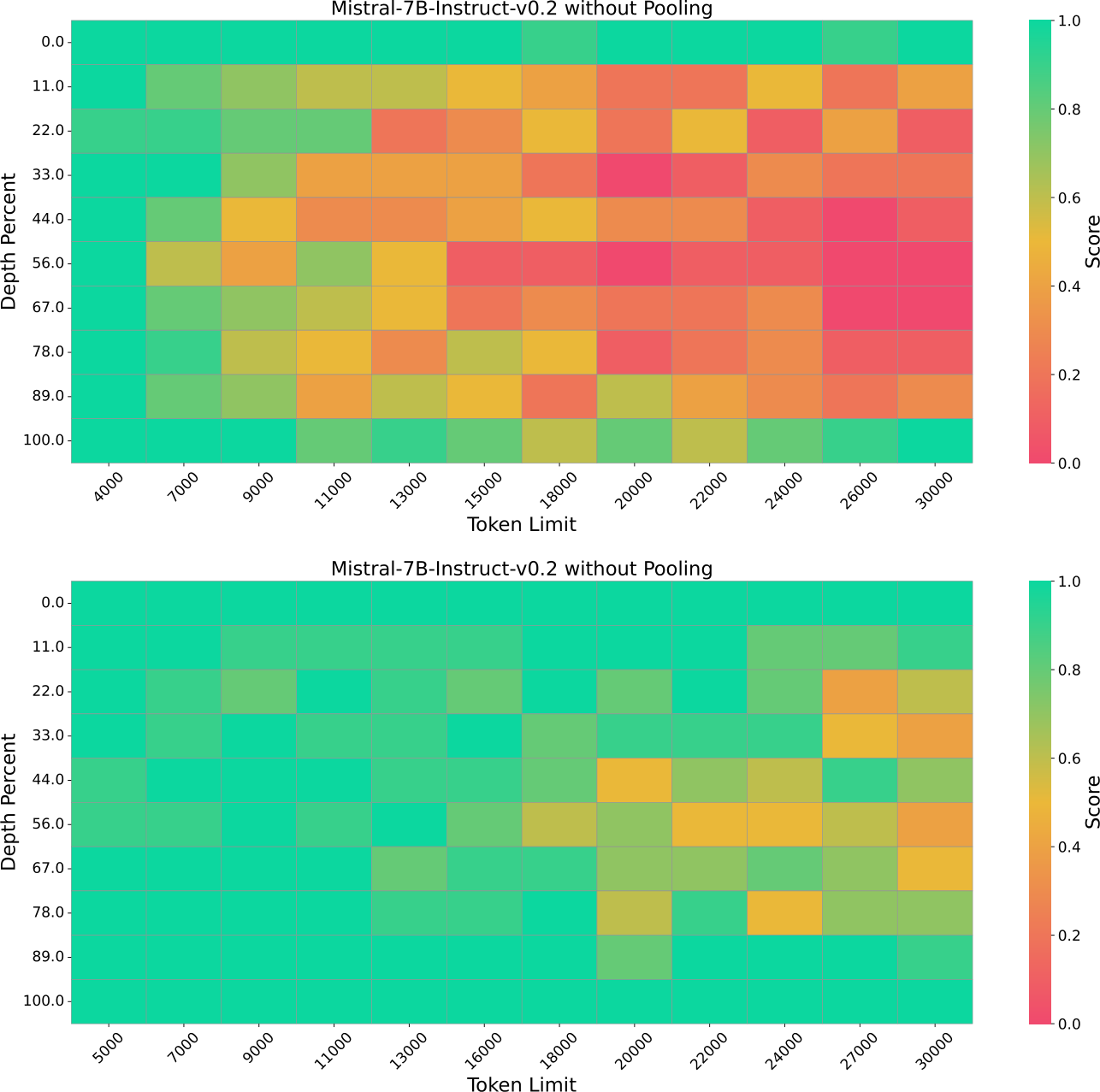
Figure 7: Ablation study of pooling on LongEval-Lines. The evaluation includes inputs, each comprised of lines formatted as "line makeshift-penguin: REGISTER_CONTENT is <10536>", where the key is an adjective-noun pair and the value is a random 5-digit number. The model needs to retrieve the value based on a given key. The x-axis denotes the length of the input; the y-axis indicates the position of the groundtruth, from 5K to 30K tokens. With the pooling, the model can retrieve correct values before 16k and performs significantly better than the one without pooling.
5.3 Experiments on LongBench
We evaluate SnapKV on these four models using LongBench [17], a multi-task benchmark designed to rigorously evaluate long context understanding capabilities across various datasets, spanning single and multi-document QA, summarization, few-shot learning, synthetic tasks, and code completion. We choose LWM-Text-Chat-1M with 1 million context length, LongChat-7b-v1.5-32k, Mistral-7B-Instruct-v0.2, Mixtral-8x7B-Instruct-v0.1 with 32k context length as our baselines. For each model, we test SnapKV with various settings: compressing KV caches in the prompt to 1024, 2048, and 4096 tokens. We use max pooling with kernel size 7 and observation window size 32. Table 1 illustrates a negligible performance drop from models with SnapKV compared with original implementations for 16 different datasets, even with prompt-KV with 1024 tokens. Some models even outperform the baseline. Our results substantiate that SnapKV can grasp the key information in the long context and give comprehensive summaries with details. Moreover, our results also indicate the effectiveness of SnapKV in compressing the prompt KV cache. For LongChat-7b-v1.5-32k, the average input token length is 12521; for LWM-Text-Chat-1M, 13422; for Mistral, 13160. Thus, using 1024, SnapKV achieves an average compression rate of 92%, and using 4096, it reaches 68%, all with negligible drops in accuracy. We compare SnapKV and H2O on the LongBench dataset to further demonstrate the performance of SnapKV. To fairly evaluate the accuracy, we set the prompt capacity for H2O to 4096. As table 1 shows, SnapKV
Table 1: Performance comparison of SnapKV and H2O across various LLMs on LongBench.
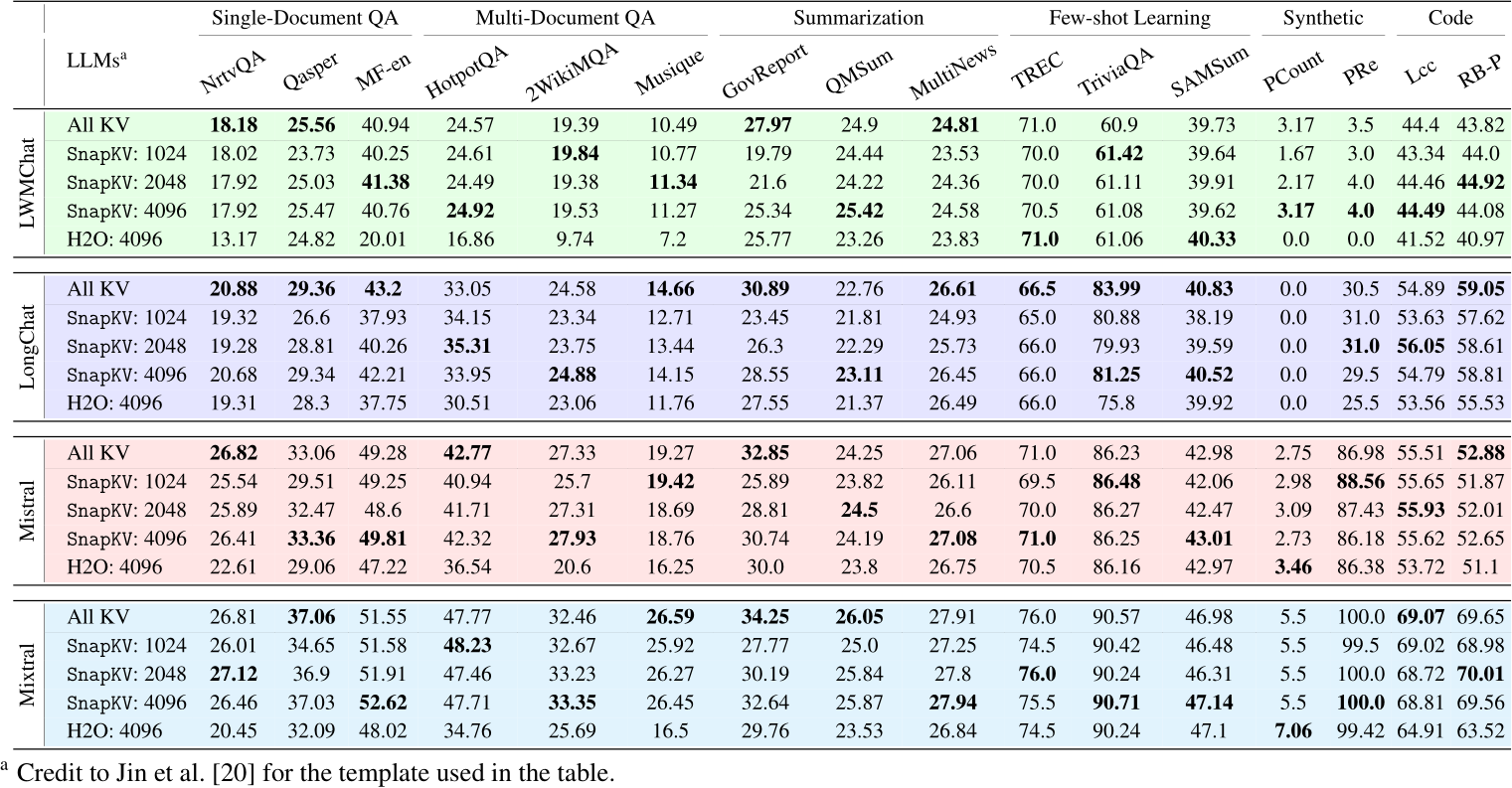
delivers significantly better performance than H2O. Even with 1024 prompt KV caches, SnapKV on Mistral-7B-Instruct-v0.2 achieves better performance than H2O with 4096 caches on 11 out of 16 benchmarks.
5.4 Experiments on Command-R
To further assess the performance of SnapKV, we conduct experiments using Cohere’s Command-R model [2], an open-source model with 35B parameters and capable of handling sequences of up to 128k token length. Command-R is designed for complex tasks requiring long context, such as retrieval-augmented generation (RAG). We extensively test Command-R on NarrativeQA and a modified version of the Needle-in-a-Haystack where it achieves promising results. To evaluate SnapKV’s impact on RAG, we ran tests on bioasq [21], multi-hop question answering with HotpotQA [22], and an internal benchmark on tool use, which further demonstrated its effectiveness. Throughout all experiments, we limit the KV cache to a maximum of 4096 tokens, while the pooling kernel size and window size are set to 13 and 64, respectively. For our evaluations, these hyper-parameters give a KV cache compression ratio between 2x to 32x depending on the sequence length.
5.4.1 Needle-in-a-Haystack
In previous experiments [23], it was noted that Needle-in-a-Haystack [18] evaluation was heavily influenced by the specific context used. To address this issue, we modify the evaluation by permuting context compositions for each length and depth combination. This approach, which we ran eight times, yielded more robust results. We observe a slight decrease in scores across all models tested under this setting compared to the original setup with no context shuffling. For simplicity, we aggregated the scores across all depths and lengths for the baseline model and the one with SnapKV. As seen in Table 2, applying SnapKV to Command-R shows no degradation in performance, even with a 128k sequence length resulting in 32x compression of KV cache.
Table 2: Needles-in-a-Haystack Test Results

5.4.2 Retrieval Augmented Generation (RAG)
We assess SnapKV’s effectiveness in RAG tasks, which are more intricate than synthetic long-context tasks like Needle-in-a-Haystack and closer to real use cases compared to tasks like NarrativeQA. RAG tasks require selecting pertinent documents from an indexed corpus based on the given prompt. An expanded context window enables the retrieval of additional documents, which can lead to improved model performance. However, this also increases memory requirements and latency, highlighting the delicate balance between retrieval scope and system resources. SnapKV proves beneficial in these tasks by reducing memory usage while enhancing the performance. We evaluated ![]() on RAG tasks with sequence lengths up to approximately 40,000 tokens.
on RAG tasks with sequence lengths up to approximately 40,000 tokens.
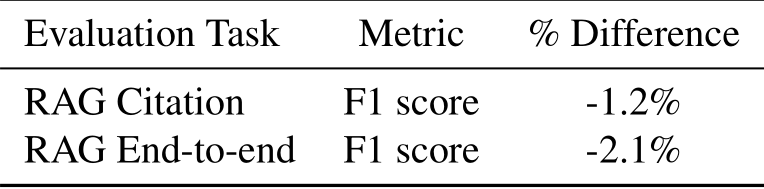
RAG Citation We begin by assessing SnapKV’s impact on the model’s ability to select relevant documents, a crucial aspect of effective RAG. We evaluate on an internal benchmarks from Cohere. The setup of the benchmark is as follow: for each prompt, we gathered a set of topic-related documents that included ground truth answers along with a sample of negative documents ensuring a total of 100 documents per prompt. We measured the model’s performance by calculating the F1-score when the model successfully retrieved the ground truth documents. The dataset employed in this experiment spanned context lengths from 20,000 to 40,000 tokens. Given our KV cache size of 4096, we achieve a compression of 5-10x. As observed in Table 3, SnapKV demonstrates a remarkable ability to retain nearly 98.8% of Command-R’s performance.
Table 3: RAG Test Results
Generation As the quality of generation is important to a model’s RAG capability, we evaluate Command-R on lost-in-the-middle and generation quality. Lost-in-the-middle is aimed to analyze whether the performance of the model varies when altering the position of ground-truth information in the context [24]. The latter is a relatively simple metric where we define the accuracy of the model to be the proportion of the ground-truth answer phrase appearing in model’s response. We conducted 3 experiments with 30, 100 and 200 sampled documents for each ground-truth. We repeat each experiment 3 times and insert the relevant documents at beginning, middle and end of the context to test SnapKV’s robustness.We report the relative difference to the baseline model. The dataset used in this phase is based on the bioasq dataset [21] with RAG-style formulation from Cohere [25].
As Table 4 shows, SnapKV is robust in terms of generation quality and does not suffer from the well-known lost-in-the-middle pathology. Moreover, SnapKV improves performance over the baseline model when the context contains close to 200 documents. One potential explanation to this is that by adequately compressing the KV cache, we can effectively reduce the noise from negative documents and push the model to construct attention scores more focused on the relevant information.
End-to-End RAG To assess SnapKV’s robustness in a comprehensive manner, we integrated it into a complete RAG pipeline. This evaluation starts by retrieving 200 documents using Cohere’s embedding service [26] in response to a given query. These documents were then re-ranked using Cohere’s re-ranking model [27], which filtered out half of the candidates, resulting in a list of 100 documents. We prompt Command-R using this list and calculate the accuracy metric as described in Section 5.4.2. We employed a modified version of the HotpotQA dataset [22] and leveraged Wikipedia as the document source. This setup introduces a more challenging set of documents as all documents, relevant or not, are semantically similar.
Table 3 showcases SnapKV’s robust performance in a production-like RAG setting. With an average dataset length of around 16,000 tokens, the KV cache benefits from a compression ratio of approximately 4x.
Table 4: RAG Generation Test Results on bioasq
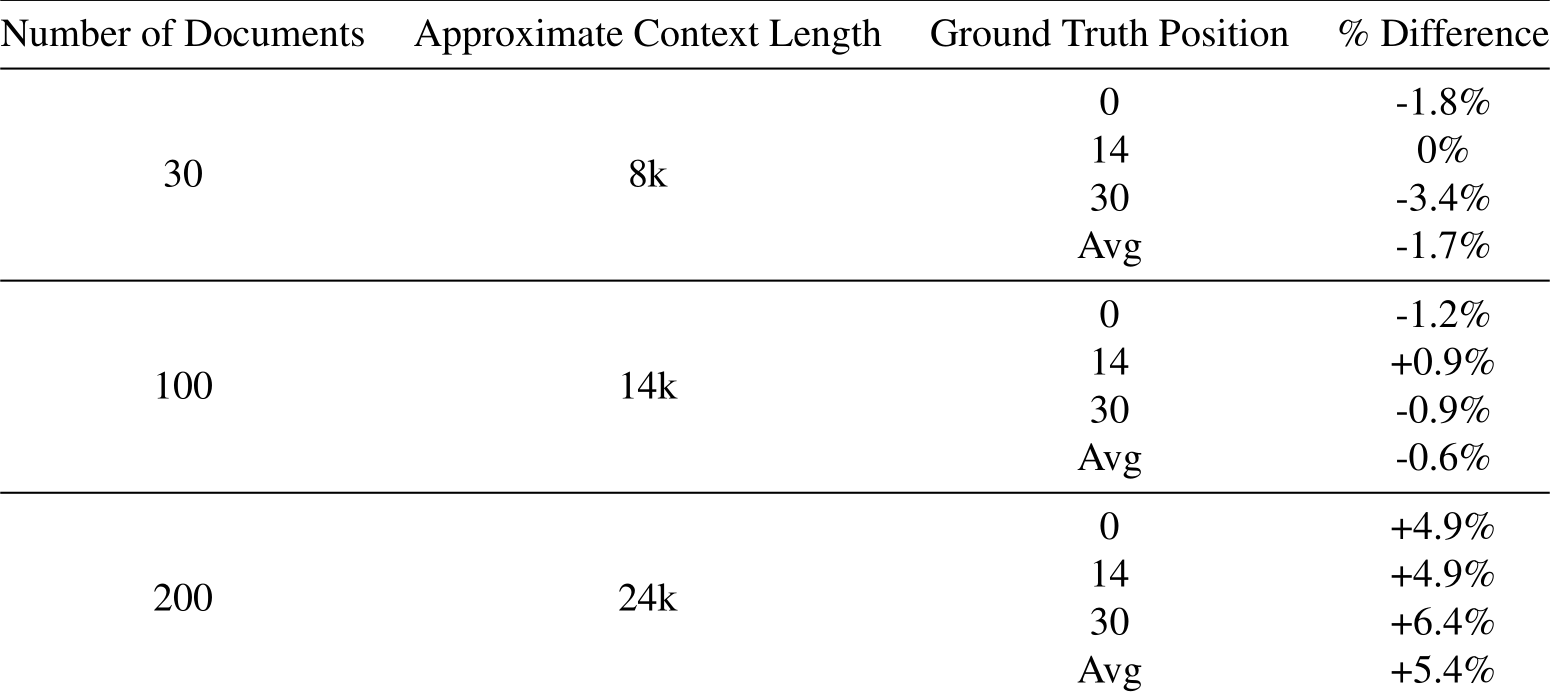
Note: For each number of sampled documents, we report the approximate context length and the difference from the baseline at each ground-truth position.
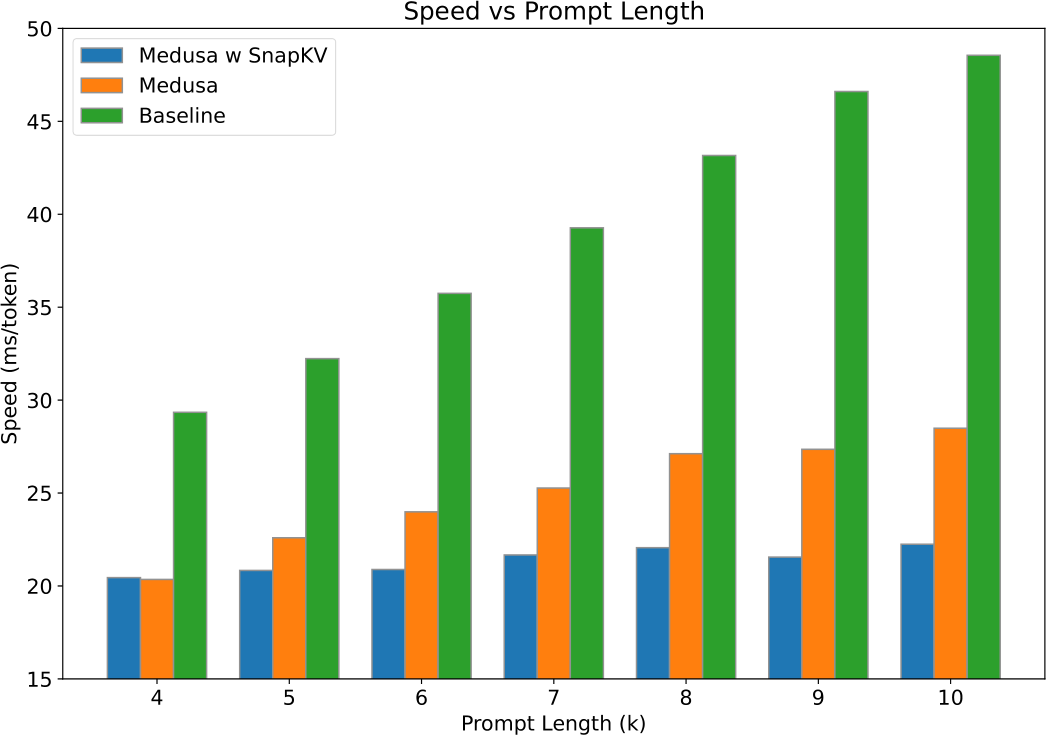
Figure 8: Comparison of generation speed (ms/token). The baseline is the Huggingface implementation of naive decoding.
5.5 Case Study: Compatibility with Parallel Decoding
In this section, we provide a novel perspective on employing KV cache compression synergistically with parallel decoding [28–32]. Parallel decoding leverages a lightweight model or an adaptor to draft initial tokens, which are subsequently verified by larger LLMs. This strategy effectively reduces memory overhead, a critical concern given the autoregressive nature of LLMs that renders them more memory-intensive than computationally demanding. Specifically, in LLMs, each decoding step involves generating a single token, with the transfer of weights between High Bandwidth Memory (HBM) and cache contributing to significant overhead [33, 34].
Our investigation incorporates ![SnapKV with Medusa [35]3](https://cdn.bytez.com/mobilePapers/v2/arxiv/2404.14469/images/12-2.png) , a cutting-edge parallel decoding framework that utilizes multiple classifiers and tree attention mechanisms for drafting tokens, subsequently verified by LLMs. One of the challenges identified is the issue of speculative decoding in processing long sequences since generating multiple tokens per decoding step introduces computational bottlenecks during long sequence processing, such as query-key matrix multiplication tiling [36]. By maintaining a constant size for the KV cache associated with prompts during generation, SnapKV enhances generation efficiency.
, a cutting-edge parallel decoding framework that utilizes multiple classifiers and tree attention mechanisms for drafting tokens, subsequently verified by LLMs. One of the challenges identified is the issue of speculative decoding in processing long sequences since generating multiple tokens per decoding step introduces computational bottlenecks during long sequence processing, such as query-key matrix multiplication tiling [36]. By maintaining a constant size for the KV cache associated with prompts during generation, SnapKV enhances generation efficiency.
Empirical results shown in Figure 8 highlight the performance across various prompt lengths, with  undergoing a maximum of 128 generation steps unless preemptively halted. The experiments utilized a subset of the QASPER [37], with a fixed prompt instructing the LLM to summarize the paper. The truncation strategy adopted aligns with LongBench [17] standards, by removing the context in the middle to achieve the desired sequence length for benchmarking.
undergoing a maximum of 128 generation steps unless preemptively halted. The experiments utilized a subset of the QASPER [37], with a fixed prompt instructing the LLM to summarize the paper. The truncation strategy adopted aligns with LongBench [17] standards, by removing the context in the middle to achieve the desired sequence length for benchmarking.
The findings indicate a slowdown in Medusa’s performance as sequence lengths extend, a challenge effectively mitigated by SnapKV’s intervention, which achieved a 1.3x speedup for sequences with 10k length compared to Medusa and a 2.2x speedup compared to the native decoding. This improvement underscores the potential of combining KV cache compression with parallel decoding frameworks to enhance LLM efficiency, particularly in long-context scenarios.
SnapKV emerges as a potent yet straightforward solution, adeptly compressing the KV caches of models to mitigate the computational and memory burdens associated with processing extensive inputs. Originating from a nuanced observation that specific tokens within prompts garner consistent attention from each head during generation, our methodology not only conserves crucial information but also enhances processing efficiency. Despite its strengths, SnapKV’s scope is primarily confined to the generative aspect of models, specifically targeting the KV caches during the generation. This limitation implies that SnapKV cannot extend a model’s long context capability if the model inherently struggles with long contexts or exhibits poor performance. Additionally, SnapKV’s design does not cover the processing of the prompt inference, which limits its effectiveness in scenarios where the system cannot handle prompts of extensive length. Nonetheless, our contributions offer significant insights and tools for the community, paving the way for more refined approaches on managing the challenges of large-scale language modeling.
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[2] Cohere. Command r: Retrieval-augmented generation at production scale, March 2024. URL https://txt.cohere.com/command-r.
[3] Anthropic. The claude 3 model family: Opus, sonnet, haiku, March 2024. URL https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/ Model_Card_Claude_3.pdf.
[4] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jeanbaptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
[5] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
[6] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36, 2024.
[7] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
[8] Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801, 2023.
[9] Bing Liu and Sahisnu Mazumder. Lifelong and continual learning dialogue systems: learning during conversation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 15058–15063, 2021.
[10] Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B Ashok, Shashank Shet, et al. Codeplan: Repository-level coding using llms and planning. arXiv preprint arXiv:2309.12499, 2023.
[11] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233, 2023.
[12] Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, et al. Qmsum: A new benchmark for query-based multi-domain meeting summarization. arXiv preprint arXiv:2104.05938, 2021.
[13] Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models. arXiv preprint arXiv:2307.11088, 2023.
[14] Stefanos Angelidis, Reinald Kim Amplayo, Yoshihiko Suhara, Xiaolan Wang, and Mirella Lapata. Extractive opinion summarization in quantized transformer spaces. Transactions of the Association for Computational Linguistics, 9:277–293, 2021.
[15] Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.
[16] Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ringattention. arXiv preprint arXiv:2402.08268, 2024.
[17] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
[18] G Kamradt. Needle in a haystack–pressure testing llms, 2023.
[19] Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. How long can context length of open-source llms truly promise? In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023.
[20] Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. Llm maybe longlm: Self-extend llm context window without tuning. arXiv preprint arXiv:2401.01325, 2024.
[21] Anastasios Nentidis, Georgios Katsimpras, Anastasia Krithara, Salvador Lima López, Eulália Farré-Maduell, Luis Gasco, Martin Krallinger, and Georgios Paliouras. Overview of bioasq 2023: The eleventh bioasq challenge on large-scale biomedical semantic indexing and question answering, 2023.
[22] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
[23] Anthropic. Long context prompting for claude 2.1, December 2023. URL https://www. anthropic.com/news/claude-2-1-prompting.
[24] Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024.
[25] Cohere. Retrieval augmented generation (rag), 2023. URL https://docs.cohere.com/ docs/retrieval-augmented-generation-rag.
[26] Cohere. Cohere embed, 2023. URL https://docs.cohere.com/reference/embed.
[27] Cohere. Cohere rerank, 2023. URL https://docs.cohere.com/docs/rerank-guide.
[28] Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. Advances in Neural Information Processing Systems, 31, 2018.
[29] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
[30] Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023.
[31] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 2023.
[32] Aonan Zhang, Chong Wang, Yi Wang, Xuanyu Zhang, and Yunfei Cheng. Recurrent drafter for fast speculative decoding in large language models. arXiv preprint arXiv:2403.09919, 2024.
[33] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
[34] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
[35] Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
[36] Tri Dao, Daniel Haziza, Francisco Massa, and Grigory Sizov. Flash-decoding for long-context inference, 2023.
[37] Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. arXiv preprint arXiv:2105.03011, 2021.
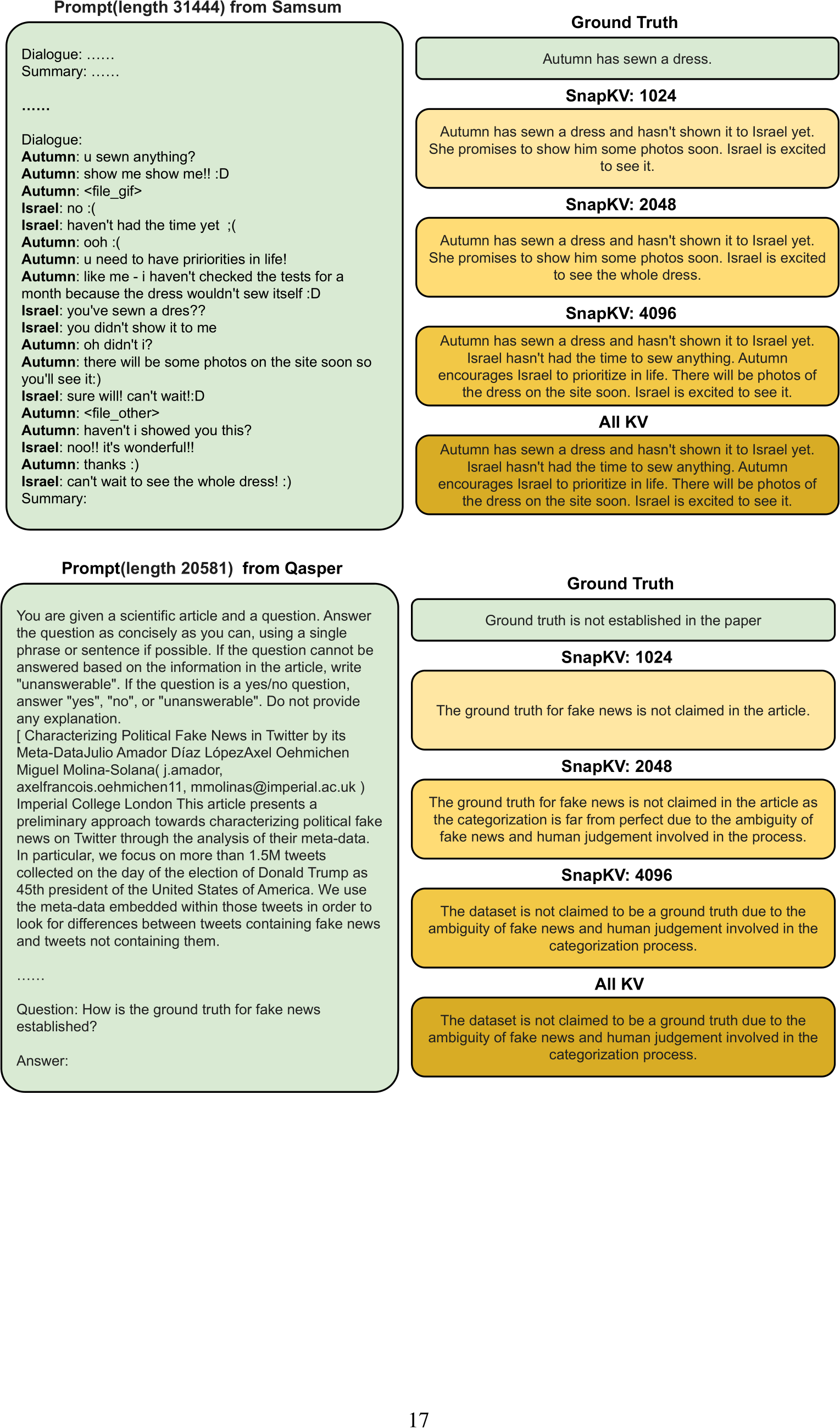
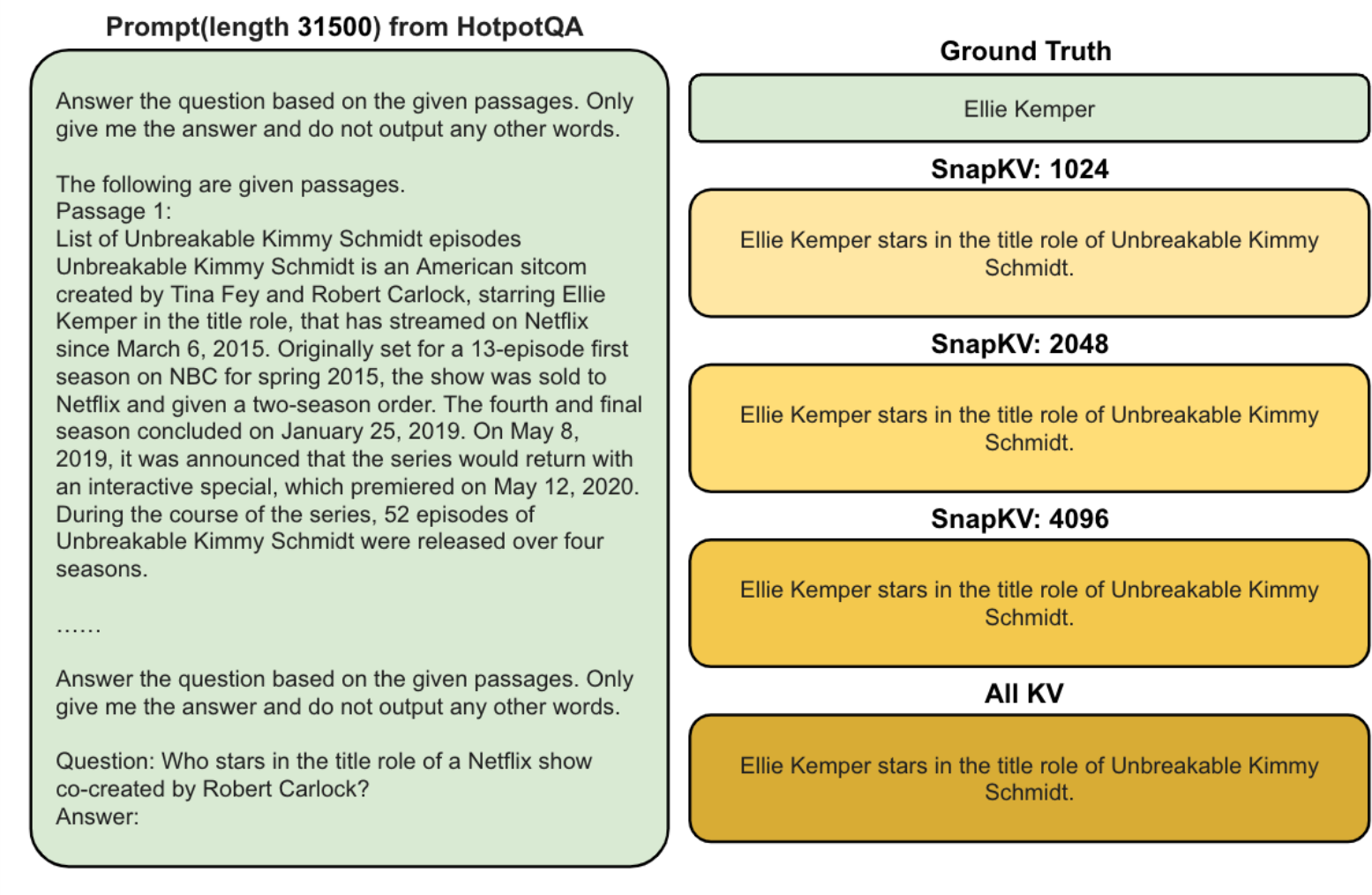
Figure 9: Visualization of generation examples from Samsum, Qasper, HotpotQA datasets with mistral-7B-instruct-v0.2. Results are compared between ground truth, SnapKV with 1024 prompt tokens, with 2048, with 4096, the baseline model with full KV cache.