We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0, estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis.
![]()
![]()
The genesis of numerous computer vision tasks lies in the estimation of camera poses and scene geometry from a set of images. It is the first fundamental step that lets us leave the image plane and venture into 3D. Since structure-from-motion (SfM) is such a central capability, we have researched it for decades. By now, refined open-source tools, such as COLMAP [82], and efficient commercial packages, such as RealityCapture [70], are available to us. Feature matchingbased SfM is the gold standard for estimating poses from images, with a precision that makes its estimates occasionally considered “ground truth” [3,5,12,44,71].
The success of Neural Radiance Fields (NeRF) [61] has renewed interest in the question of whether SfM can be solved differently, based on neural, implicit scene representations rather than 3D point clouds. There has been some progress in recent years but, thus far, learning-based approaches to camera pose recovery

Fig. 1: Reconstructing 10,000 Images. Top: Starting from a single image and the identity pose, we train a learning-based visual relocalizer. The relocalizer allows us to estimate the poses of more views, and the additional views allow us to refine the relocalizer. We show three out of six iterations for this scene (7Scenes Office [83]). All 10k images have been posed in roughly 1 hour on a single GPU. In comparison NoPe-NeRF [10] needs two days to pose 200 images. The point cloud is a visualization of the implicit scene representation of the relocalizer. Camera positions are color coded by relocalization confidence from yellow (low) to green (high). Bottom: Point clouds from Nerfacto [91] trained on top of our poses for a few scenes from our experiments.
still have significant limitations. They either require coarse initial poses [43,53, 100, 103], prior knowledge of the pose distribution [60] or roughly sequential inputs [10]. In terms of the number of images that learning-based approaches can handle, they are either explicitly targeted at few-frame problems [52,84,97, 98,101,105] or they are computationally so demanding that they can realistically only be applied to a few hundred images at most [10,53,100]. We show that none of these limitations are an inherent consequence of using learning-based scene representations.
Our approach is inspired by incremental SfM and its relationship to another computer vision task: visual relocalization. Visual relocalization describes the problem of estimating the camera pose of a query image w.r.t. to an existing scene map. Incremental SfM can be re-interpreted as a loop of 1) do visual relocalization to register new views to the reconstruction, and 2) refine/extend the reconstruction using the newly registered views. Local feature matching is a traditional approach to visual relocalization [72,76–78]. In recent years, multiple learning-based relocalizers have been proposed that encode the scene implicitly in the weights of a neural network [3, 11, 13, 14, 16, 21, 46]. Not all of them are suitable for building a SfM pipeline. We need a relocalizer with high accuracy and good generalization. Training of the relocalizer has to be swift. We need to be able to bootstrap relocalization without ground truth poses. And we need to be able to tell whether registration of a new image was successful.
We show that “scene coordinate regression”, an approach to visual relocalization proposed a decade ago [83], has the desirable properties and can serve as the core of a new approach to learning-based SfM: Scene coordinate reconstruction. Rather than optimizing over image-to-image matches, like feature-based SfM, scene coordinate reconstruction regresses image-to-scene correspondences directly. Rather than representing the scene as a 3D point cloud with high dimensional descriptors, we encode the scene into a lightweight neural network. Our approach works on unsorted images without pose priors and efficiently optimises over thousands of images, see Fig. 1.
We summarize our contributions:
– Scene Coordinate Reconstruction, a new approach to SfM based on incremental learning of scene coordinate regression, a visual relocalization principle.
– We turn the fast-learning visual relocalizer ACE [11] into a SfM framework that is able to predict the camera poses of a set of unposed RGB images. We refer to this new SfM pipeline as ACE0 (ACE Zero).
– Compared to ACE [11], we add the capability to train in a self-supervised fashion. We start from a single image, and iterate between learning the map and registering new views. We expedite reconstruction times by early stopping, and increase reconstruction quality by pose refinement.
Reconstruction. SfM pipelines either ingest a collection of unordered images [19,80,86] or an ordered image sequence [6,29,65,68,90] from a video to recover 3D structure of a scene and camera poses (“motion”) of the images.
SIFT [58] and other robust feature descriptors allow matching image features across wide baselines enabling systems to reconstruct large-scale scenes using Internet images [82, 86, 87, 102]. Feature tracks are built by matching the local features between two or more images. In our work we do not explicitly compute matches between images, which can be computationally expensive.
Feature tracks and estimated relative poses are used to solve for the 3D feature coordinates, camera poses and calibrations (intrinsic matrices). This geometric optimization problem is mainly solved using bundle adjustment which was explored in photogrammetry and geodesy [18, 49] and became standard in the computer vision community [39,94]. Bundle adjustment relies on the initialization being close to the solution (i.e., camera poses and 3D points are already mostly accurate). There are two main approaches to this problem. Incremental SfM [6, 68] starts the reconstruction from very few images to create a highquality seed reconstruction that progressively grows by registering more images and refining the reconstruction until convergence. Global SfM approaches solve for “global” poses of all images using estimates of relative poses, i.e., motion averaging [36, 37], rotation averaging [38, 59] and pose-graph optimization [20]. Our work is similar to Incremental SfM, as we also progressively register images to the reconstructed scene starting from a seed reconstruction.
Various techniques were proposed to improve SfM runtime for very large sets of images [1,2,8,9,27,35,40,88,93].
Visual Relocalization. A reconstructed (or mapped) scene is a database of images with known camera poses. This database can be used by a visual relocalizer to estimate poses for new query images to “relocalize” a camera in the scene. Feature-based approaches extract 2D local features [30,32,55,58,73,74,89] from a query image and match them to 3D points to solve for the query pose using perspective-n-point (PnP) solvers [34], e.g., [75–77]; or match query features to 2D local features of mapped images to triangulate the query image, e.g., [107, 108]. For large scenes, matching features on a subset of database images relevant to the query can improve the speed and accuracy, e.g., [41,69,72,78].
Some learning-based approaches encode the map of a scene in the weights of a neural network. PoseNet [46] directly regresses the absolute camera pose given an input image using a CNN that was trained on image-pose pairs of the reconstructed scene. Sattler et al. show that extrapolating outside the mapped poses can be challenging for absolute pose regression approaches [79]. Relative pose regression networks [3,4,31,50,95] estimate the relative pose for a pair of images, allowing triangulation of the query image from multiple map images, or even a single-image. Scene coordinate regression [11,13,14,16,21,22,51,83] directly predicts 3D coordinates of a point given a patch. This approach generalizes well as the camera pose is solved using PnP [34] within a RANSAC loop [33]. ACE [11] shows that training of scene coordinate regression can be greatly accelerated. In our work we train the ACE localizer, but we start from images without poses.
Image-Based Rendering. In recent years, neural radiance fields (NeRFs) [61] have seen a lot of attention from the community. NeRFs allow photorealistic novel view synthesis when trained from image-pose pairs. Typically, estimation of the image poses is done in advance by using an SfM pipeline such as COLMAP, e.g., [5]. Nonetheless, research exists that estimates camera poses with NeRFs, facilitates camera localization for novel views after NeRF training [23–25,62,104], or simultaneously estimates camera poses during NeRF training from images alone [10,26,53,84,100]. However, these approaches either assume that the scene is captured from the front [43,100, 103], that coarse poses are available for initialization [53], or that images are captured sequentially [10]. Techniques that rely on a multi-layer perceptron (MLP) representation of the scene, e.g. [10,26], are slow to train, taking days to converge. While radiance fields can be trained faster using multi-layer hash grids [63] or Gaussian splats [47], their efficacy in pose estimation without approximate prior pose initialization [54,62] or sequential image inputs [47] remains unproven. Concurrently, several learning-based camera pose estimation methods have been proposed [52,98,105]. Due to GPU memory constraints, these methods estimate poses for sparse sets of images.
Preliminaries. The input to our system is a set of RGB images, denoted by I = ![]() , where i refers to the image index. Our system estimates the corresponding set of camera parameters, both intrinsics and extrinsics:
, where i refers to the image index. Our system estimates the corresponding set of camera parameters, both intrinsics and extrinsics: ![]() . Each
. Each 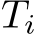
Scene Coordinate Regression CNN feature backbone MLP frozenparametersImages
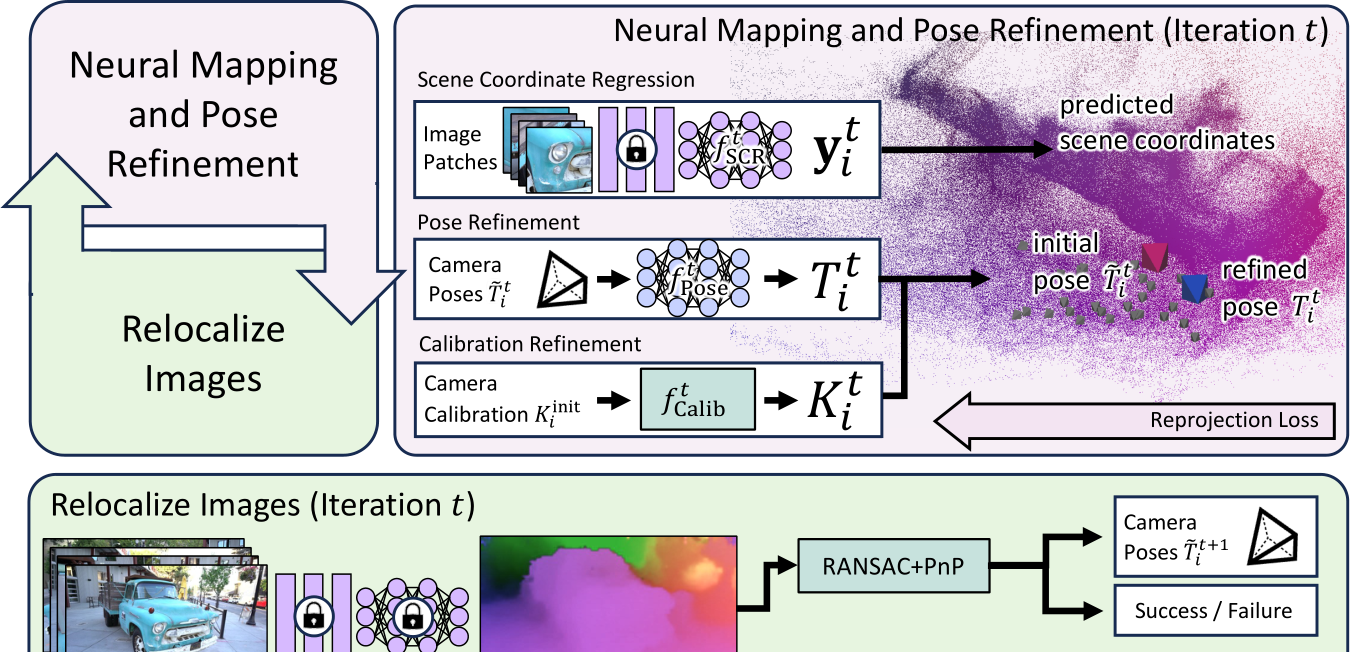
Fig. 2: ACE0 Framework. Top left: We loop between learning a reconstruction from the current set of images and poses (“neural mapping”), and estimating poses of more images (“relocalization”). Top right: During the mapping stage, we train a scene coordinate regression network as our scene representation. Camera poses of the last re-localization round and camera calibration parameters are refined during this process. We visualize scene coordinates by mapping XYZ to the RGB cube. Bottom: In the re-localization stage, we re-estimate poses of images using the scene coordinate regression network, including images that were previously not registered to the reconstruction. If the registration of an image succeeds, it will be used in the next iteration of the mapping stage; otherwise it will not.
refers to a ![]() matrix containing a rotation and translation, while
matrix containing a rotation and translation, while 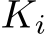 refers to a
refers to a ![]() matrix with the calibration parameters. We assume no particular image order or any prior knowledge about the pose distribution.
matrix with the calibration parameters. We assume no particular image order or any prior knowledge about the pose distribution.
We also want to recover the 3D structure of the scene: Each pixel j in image i with 2D pixel position 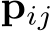 has a corresponding coordinate in 3D, denoted as
has a corresponding coordinate in 3D, denoted as 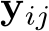 . 2D pixel positions and 3D scene coordinates are related by the camera pose and the projection function
. 2D pixel positions and 3D scene coordinates are related by the camera pose and the projection function ![]() :
:
![]()
where 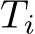 maps camera coordinates to scene coordinates, and
maps camera coordinates to scene coordinates, and 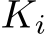 projects camera coordinates to the image plane.
projects camera coordinates to the image plane.
As our scene representation, we utilize a scene coordinate regression model [83], i.e., a learnable function ![]() that maps an image patch of image
that maps an image patch of image 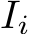 , centered around pixel position
, centered around pixel position 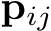 to a scene coordinate:
to a scene coordinate: 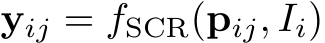 .
.
Given a set of 2D-3D correspondences predicted by ![]() for any image
for any image 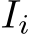 , we can recover this image’s camera pose
, we can recover this image’s camera pose 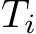 using a pose solver g:
using a pose solver g:
![]()
Since 2D-3D correspondences can be inaccurate, and contain incorrect predic- tions, g combines a PnP solver [34] with a RANSAC loop [33].
Normally, scene coordinate regression models are trained in a supervised fashion for the task of visual relocalization [11, 13, 14, 16, 21, 22, 51, 83]. That is, ![]() is trained using images with known ground truth camera parameters
is trained using images with known ground truth camera parameters 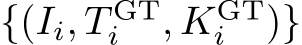 , and used for estimating the poses of unseen query images. Instead, we show how these models can be trained self-supervised, without ground truth poses, to estimate the poses of the mapping images themselves. Thus, we turn scene coordinate regression into scene coordinate reconstruction, a learning-based SfM tool.
, and used for estimating the poses of unseen query images. Instead, we show how these models can be trained self-supervised, without ground truth poses, to estimate the poses of the mapping images themselves. Thus, we turn scene coordinate regression into scene coordinate reconstruction, a learning-based SfM tool.
3.1 Neural Mapping
We train the scene coordinate regression model iteratively where we denote the current time step as t and the corresponding scene model as 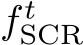 . We iterate between training the scene model, and registering new views, see Fig. 2.
. We iterate between training the scene model, and registering new views, see Fig. 2.
At iteration t we assume that a subset of images has already been registered to the scene, 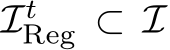 , and where corresponding camera parameters,
, and where corresponding camera parameters, 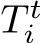 and
and 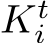 , have already been estimated. Using these as pseudo ground truth, we train the scene model by minimizing the pixel-wise reprojection error:
, have already been estimated. Using these as pseudo ground truth, we train the scene model by minimizing the pixel-wise reprojection error:
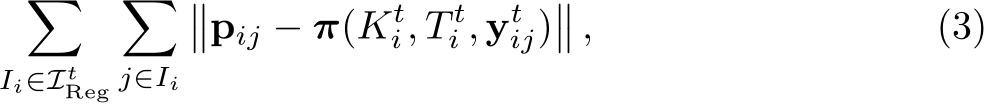
where the scene model 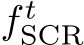 predicts coordinates
predicts coordinates 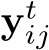 .
.
Mapping Framework. We optimize Eq. 3 using stochastic gradient descent, using the fast-learning scene coordinate regressor ACE [11] (Accelerated Coordinate Encoding). ACE is trained in minutes, even for thousands of views. Since we have to train the model in multiple iterations, each individual iteration must be done quickly. ACE approximates Eq. 3 by sampling random patches from the training set, 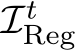 . To do that efficiently, ACE employs a pre-trained encoder to pre-compute high dimensional features for a large number of training patches. The encoder stays frozen during mapping. The actual scene model, which is trained, is a multi-layer perceptron (MLP) that maps encoder features to scene coordinates; see Fig. 2 (top right) for a visual representation.
. To do that efficiently, ACE employs a pre-trained encoder to pre-compute high dimensional features for a large number of training patches. The encoder stays frozen during mapping. The actual scene model, which is trained, is a multi-layer perceptron (MLP) that maps encoder features to scene coordinates; see Fig. 2 (top right) for a visual representation.
Pose Refinement. Differently from ACE [11] protocol, the ground truth poses 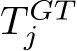 are unknown during training. Instead, we have
are unknown during training. Instead, we have 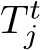 , estimates based on earlier iterations of the reconstruction. Since these estimates can be inaccurate, we add the ability to refine poses during mapping. We implement refinement using an MLP:
, estimates based on earlier iterations of the reconstruction. Since these estimates can be inaccurate, we add the ability to refine poses during mapping. We implement refinement using an MLP:
![]()
where 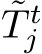 denotes the initial pose estimate at the start of a mapping iteration. The refinement MLP ingests
denotes the initial pose estimate at the start of a mapping iteration. The refinement MLP ingests 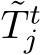 as
as ![]() values and predicts 12 additive offsets. We jointly optimize
values and predicts 12 additive offsets. We jointly optimize 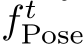 and
and 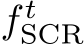 to minimize reprojection error 3. We orthonormalize the rotation using Procrustes [17] to make the pose a valid rigid
to minimize reprojection error 3. We orthonormalize the rotation using Procrustes [17] to make the pose a valid rigid
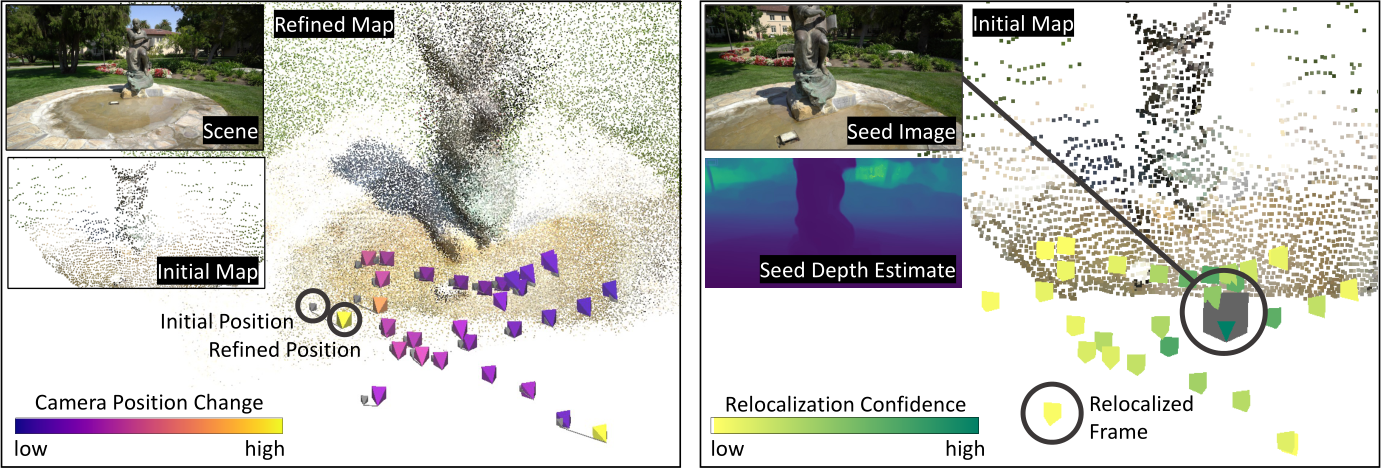
Fig. 3: Left: Pose Refinement. Since we register images based on a coarse and incomplete state of the reconstruction, we add the ability to refine poses during neural mapping. An MLP predicts pose updates relative to the initial poses, supervised by the reprojection error of scene coordinates. Right: Initialization. To start the reconstruction, we train the network using one image, the identity pose and a depth estimate, here ZoeDepth [7]. In this example, we register 33 views to the initial reconstruction. Depth estimates are only used for this step.
body transformation. We show the impact of pose refinement for one iteration in Fig. 3 (left).
We discard the refinement MLP after each mapping iteration. Its purpose is to enable the scene model, 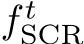 , to converge to a consistent scene representation. With neither poses nor 2D-3D correspondences fixed in Eq. 3, the scene coordinate regressor could drift or degenerate. As regularization, we optimize the pose refiner
, to converge to a consistent scene representation. With neither poses nor 2D-3D correspondences fixed in Eq. 3, the scene coordinate regressor could drift or degenerate. As regularization, we optimize the pose refiner 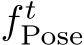 using AdamW [57] with weight decay, biasing the MLP to predict small updates. We found no further regularization necessary. The smoothness prior of the networks [96] encourages a multi-view consistent solution.
using AdamW [57] with weight decay, biasing the MLP to predict small updates. We found no further regularization necessary. The smoothness prior of the networks [96] encourages a multi-view consistent solution.
As an alternative, we could back-propagate directly to the input poses [100, 104] to update them. However, when optimizing over thousands of views, the signal for each single pose becomes extremely sparse. Cameras are also correlated via the scene representation. If the optimization removes drift in the scene representation, multiple cameras have to be moved. The refinement MLP is an effective means to model the correlation of cameras.
Calibration Refinement. We do not assume information about precise calibration parameters, although that information is often reported by devices and, e.g. stored in the EXIF data. We do rely on a sensible initialization, assuming that the principal point is in the center, that pixels are unskewed and square. We do not model image distortion. While these are reasonable assumptions for many data regimes, we cannot rely on the focal length to be given. Thus, we refine the focal length via a utility function starting from a heuristic: 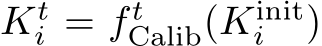 . The refinement function entails a single learnable parameter
. The refinement function entails a single learnable parameter 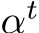 such that the focal length
such that the focal length 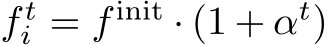 . We optimize
. We optimize 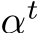 using AdamW [57] with weight decay, biasing it towards a small relative scale factor. We set
using AdamW [57] with weight decay, biasing it towards a small relative scale factor. We set 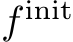 to 70% of the image diagonal and it is typically a parameter shared by all cameras.
to 70% of the image diagonal and it is typically a parameter shared by all cameras.
3.2 Relocalization
Given the scene model of iteration t, we attempt to register more images to determine the training set for the next mapping iteration, 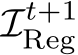 . We pass all images in I to the scene coordinate regressor
. We pass all images in I to the scene coordinate regressor  to gather 2D-3D correspondences, and solve for their poses using RANSAC and PnP:
to gather 2D-3D correspondences, and solve for their poses using RANSAC and PnP:
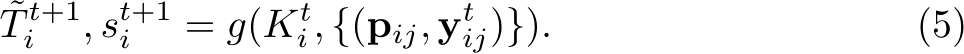
Here, we assume that the pose solver returns a confidence score 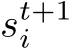 alongside the pose itself that lets us decide whether the pose of the image has been estimated successfully. We simply utilize the inlier count as score
alongside the pose itself that lets us decide whether the pose of the image has been estimated successfully. We simply utilize the inlier count as score 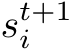 and apply a threshold to form the training set of the next mapping iteration:
and apply a threshold to form the training set of the next mapping iteration: 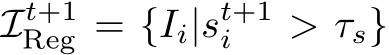 . The relocalization process is depicted in Fig. 2, bottom.
. The relocalization process is depicted in Fig. 2, bottom.
3.3 Initialization
We start the reconstruction with one image: 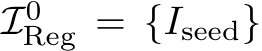 . We set the seed pose
. We set the seed pose 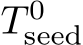 to identity, and we initialize the calibration
to identity, and we initialize the calibration 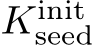 as explained above.
as explained above.
We cannot train a scene coordinate regression network using Eq. 3 with a single image. The reprojection error is ill-conditioned without multiple views constraining the depth. Therefore, we optimize a different objective in the seed iteration, inspired by Map-free Relocalization [3]. Arnold et al. argue that a single image and a depth estimate are sufficient to relocalize query images. Our experiments show that a few coarse estimates are enough to serve as initialization for optimizing the reprojection error according to Eq. 3.
Let 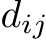 be a depth value predicted for pixel j of image i. We derive a target scene coordinate by back-projection as
be a depth value predicted for pixel j of image i. We derive a target scene coordinate by back-projection as 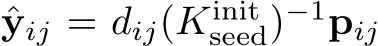 . We train an ini- tial scene coordinate regression network
. We train an ini- tial scene coordinate regression network 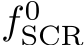 by optimizing
by optimizing 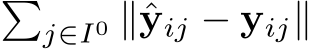 . Fig. 3 (right) shows a scene coordinate point cloud learned from a depth estimate, and successful relocalization against it.
. Fig. 3 (right) shows a scene coordinate point cloud learned from a depth estimate, and successful relocalization against it.
We found our pipeline to be robust w.r.t. selecting the seed image. However, when a randomly selected image has little to no visual overlap with the remaining images, the whole reconstruction would fail. Selecting an unfortunate seed image, e.g., at the very end of a long camera trajectory, can increase reconstruction times. To decrease the probability of such incidents, we try 5 random seed images and choose the one with the highest relocalization rate across 1000 other mapping images. Since mapping seed images is fast, ca. 1 min on average, this poses no significant computational burden.
3.4 Implementation
We base our pipeline on the public code of the ACE relocalizer [11]. ACE uses a convolutional feature backbone, pre-trained on ScanNet [28], that ingests images scaled to 480px height. On top of the backbone is the mapping network, a 9-layer MLP with 512 channels, consuming 4MB of weights in 16-bit floating point precision. This is our scene representation.
The ACE training process is reasonably fast, taking 5 minutes to train the scene network. Since we repeat training the scene network in multiple iterations, we expedite the process further to decrease our total reconstruction time. Adaptive Sampling of Training Patches. ACE trains the scene representation based on 8M patches sampled from the mapping images, a process that takes 1 minute. This is excessive when having very few mapping images in the beginning of the reconstruction, thus we loop over the mapping images at most 10 times when sampling patches, or until 8M patches have been sampled. Using this adaptive strategy, sampling patches for the seed reconstruction where we have 1 image only takes 2 seconds instead of 1 minute. Adaptive Stopping. ACE trains the scene model using a fixed one-cycle learning rate schedule [85] to a total of 25k parameter updates. We make the training schedule adaptive since the network is likely to converge fast when trained on few images only. We monitor the reprojection error of scene coordinates within a mini-batch. If for 100 consecutive batches 70% of reprojection errors are below an inlier threshold of 10px, we stop training early. We approximate the one-cycle learning rate schedule in a linear fashion: we increase the learning rate in the first 1k iteration from 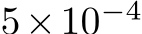 to
to 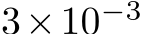 and when the early stopping criterion has been met, we decrease the learning rate to
and when the early stopping criterion has been met, we decrease the learning rate to 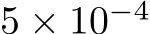 within 5k iterations.
within 5k iterations.
We report more implementation details and hyper-parameters in the supplement. We will also make our code publicly available to ensure reproducibility.
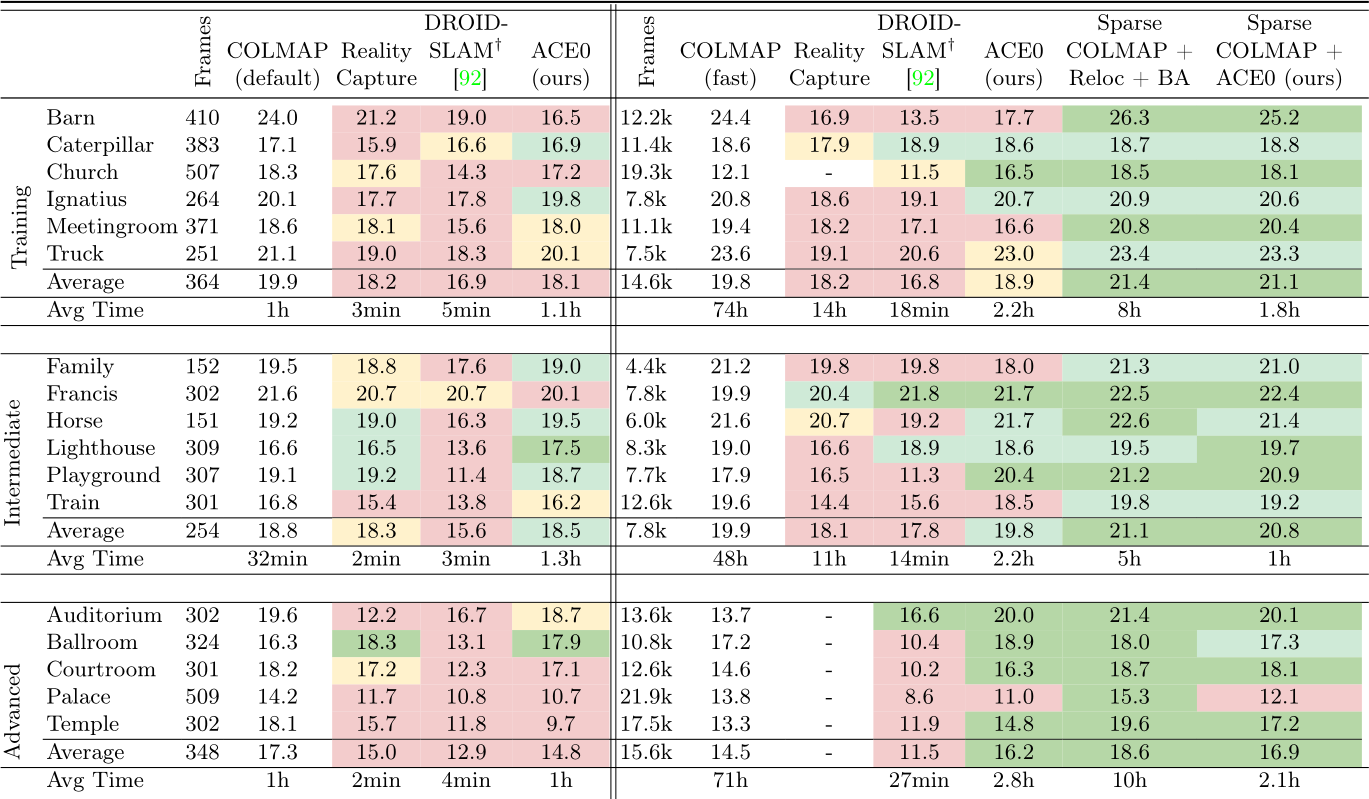
We refer to our SfM pipeline as ACE0 (ACE Zero) since it builds on top of the ACE relocalizer [11] but adds the ability to train from scratch, without poses. We demonstrate the effectiveness of our approach on three datasets and 31 scenes in total. For all experiments, we rely on ZoeDepth [7] to initialize our reconstructions. All timings reported for ACE0 are based on a single V100 GPU. Baselines. We consider the pose estimates of COLMAP with default parameters as our pseudo ground truth, obtained by extensive processing. We also run COLMAP with parameter settings recommended for large image collections of 1k images and more [81]. This variation achieves much faster processing for a slight drop in quality (denoted COLMAP fast). We use a V100 GPU for COLMAP feature extraction and matching, and we specify the exact parameters of COLMAP in the supplement. Furthermore, we show some results of RealityCapture [70], an efficient commercial feature-based SfM pipeline.
We compare to learning-based SfM approaches that are not restricted to few-frame scenarios, namely to NeRF-based BARF [53] and NoPe-NeRF [10]. We also compare to DUSt3R [98], a non-NeRF learning-based SfM method. While we focus on reconstructing unsorted image collections, the datasets we consider allow for sequential processing. Hence, for context, we also show results of DROID-SLAM [92], a neural SLAM approach. Unless specified otherwise, we report timings based on a single V100 GPU.
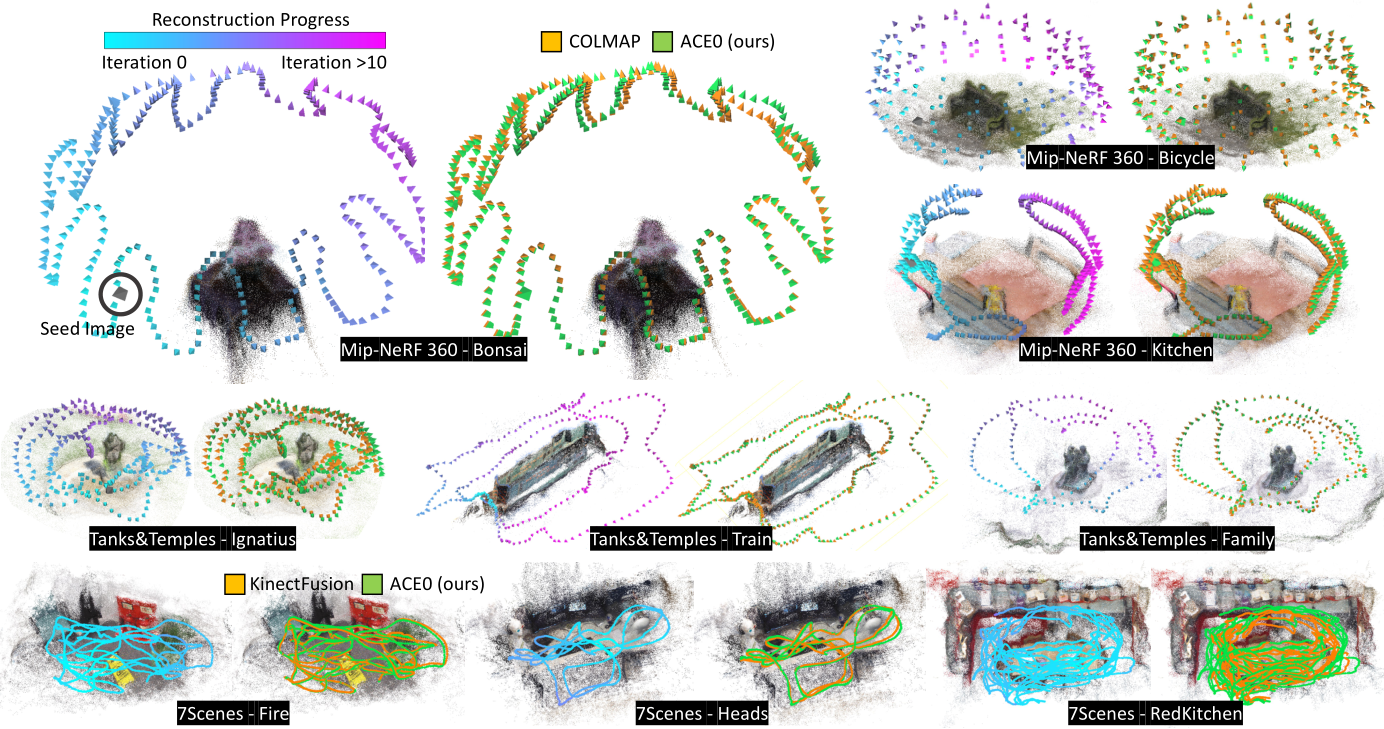
Fig. 4: Reconstructed Poses. We show poses estimated by ACE0 for a selection of scenes. We color code the reconstruction iteration in which a particular view has been registered. We show the ACE0 point cloud as a representation of the scene. The seed image is shown as a gray frustum. We also compare our poses to poses estimated by COLMAP (Mip-NeRF 360, Tanks and Temples) and KinectFusion (7-Scenes).
Benchmark. We show results on 7-Scenes [83], a relocalization dataset, on Mip-NeRF 360 [5], a view synthesis dataset and on Tanks and Temples [48], a reconstruction dataset. Comparing poses on these datasets is problematic, as our pseudo ground truth is estimated rather than measured. For example, an approach might be more accurate than COLMAP on individual scenes. Computing pose errors w.r.t. COLMAP would result in incorrect conclusions. Therefore, we gauge the pose quality in a self-supervised way, using novel view synthesis.
We let each method estimate the poses of all images of a scene. For evaluation, we split the images into training and test sets. We train a Nerfacto [91] model on the training set, and synthesize views for the test poses. We compare the synthesized images to the test images and report the difference as peak signal-to-noise ratio (PSNR). To ensure a fair comparison to NeRF-based competitors, we use these methods in the same way as the other SfM methods: we run them to pose all images, and train a Nerfacto model on top of their poses. This is to ensure that we solely compare the pose quality across methods, and not different capabilities in view synthesis. The quality of poses affects the PSNR numbers in two ways: Good training poses let the NeRF model fit a consistent scene representation. Good testing poses make sure that the synthesized images are aligned with the original image. We explain further details including perceptual metrics in the supplement. In spirit, our evaluation is similar to the Tanks and Temples benchmark which evaluates a derived scene mesh rather than camera poses. However, our evaluation can be applied to arbitrary datasets as it does not need ground truth geometry.
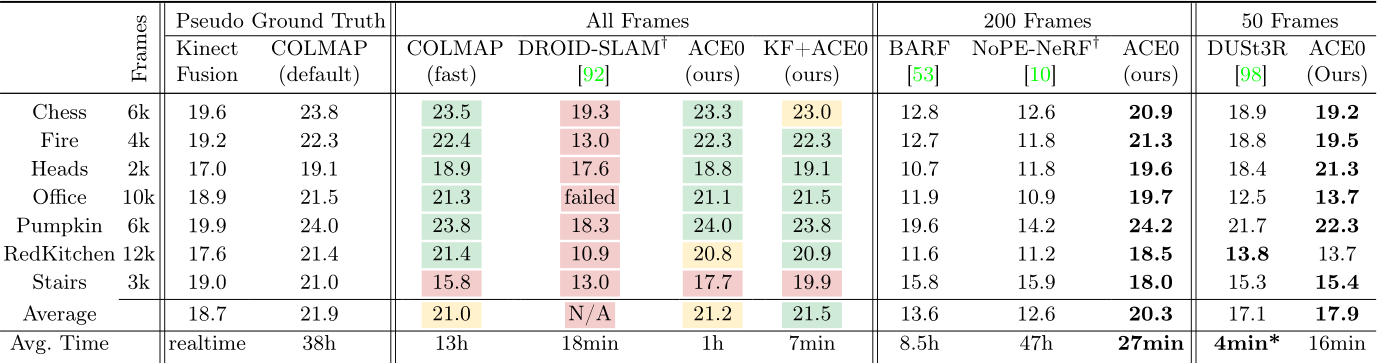
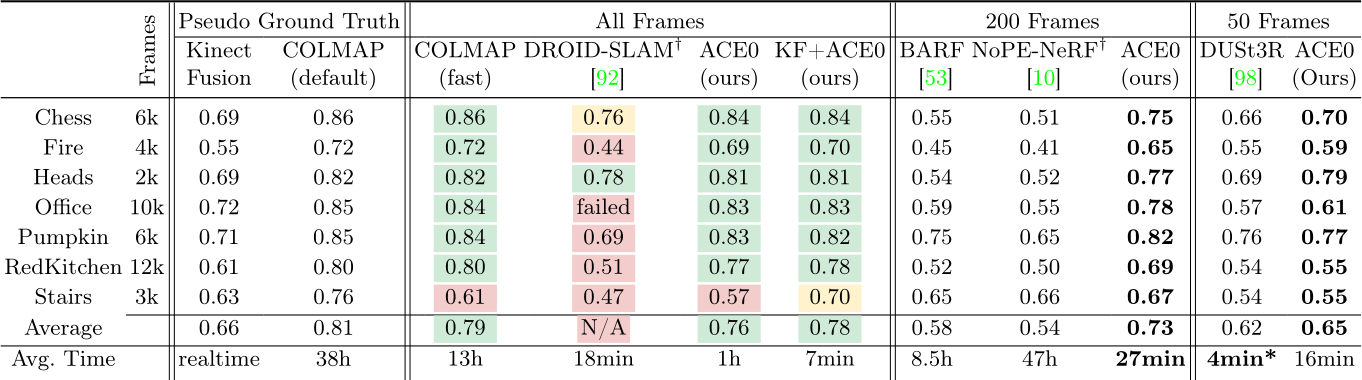
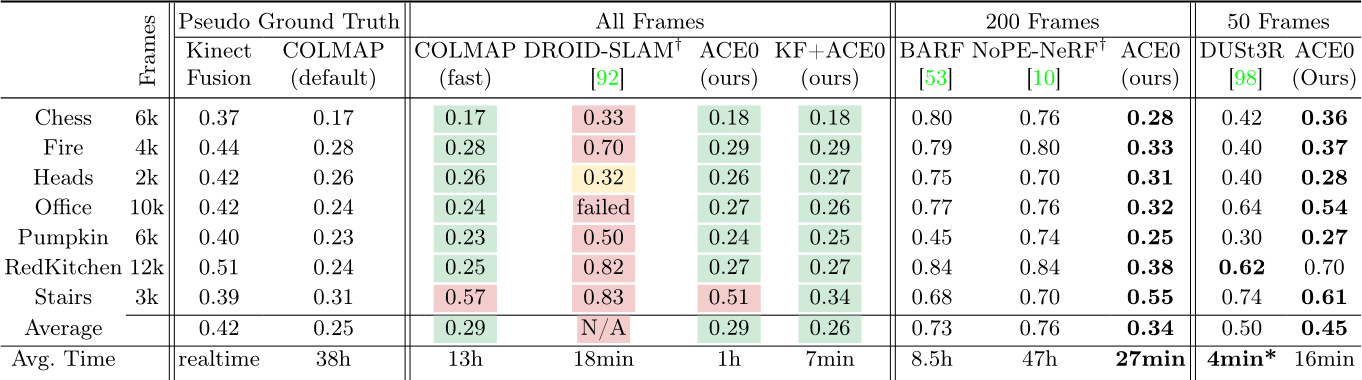
Table 1: 7-Scenes. We show the pose accuracy via view synthesis with Nerfacto [91] as PSNR in dB, and the reconstruction time. Results for All Frames are color coded w.r.t. similarity to the COLMAP pseudo ground truth: > 0.5 dB better within ![]() 1 dB worse . For some competitors, we had to sub-sample the images due to their computational complexity (right side).
1 dB worse . For some competitors, we had to sub-sample the images due to their computational complexity (right side). ![]() Method needs sequential inputs.
Method needs sequential inputs. ![]() Results on more powerful hardware.
Results on more powerful hardware.
4.1 7-Scenes
The 7-Scenes dataset [83] consists of seven indoor scenes, scanned with a Kinect v1 camera. Multiple, disconnected scans are provided for each scene to a total of 2k-12k images. For each method, we assume a shared focal length across scans and initialize with the default calibration of a Kinect v1. The dataset comes with pseudo ground truth camera poses estimated by KinectFusion [42, 64], a depth-based SLAM system. Individual scans were registered but not bundle-adjusted [12]. Inspired by [12], we recompute alternative, bundle-adjusted pseudo ground truth by running COLMAP with default parameters. Discussion. We show results in Table 1. Of both pseudo ground truth versions, KinectFusion achieves lower PSNR numbers than COLMAP, presumably due to the lack of global optimization. COLMAP with fast parameters shows only slightly lower PSNR numbers than COLMAP with default parameters. Both versions of running COLMAP take considerable time to reconstruct each scene. We note that COLMAP has been optimised for quality, rather than speed. Not all acceleration strategies from the feature-based SfM literature have been implemented in COLMAP, so presumably comparable quality can be obtained faster. DROID-SLAM [92] largely fails on 7-Scenes, presumably due to the jumps between individual scans of each scene.
Our approach, ACE0, achieves a pose quality comparable to the COLMAP pseudo ground truth while reconstructing each scene in ![]() 1 hour despite the large number of images. We show qualitative examples in Figure 4. We also demonstrate that ACE0 can swiftly optimize an initial set of approximate poses. When starting from KinectFusion poses, ACE0 increases PSNR significantly in less than 10 minutes per scene. In the supplement, we include a parameter study on 7-Scenes to show that ACE0 is robust to the choice of depth estimator. We also show the positive impact of pose refinement on the reconstruction quality as well as the reconstruction speedup due to our early stopping schedule.
1 hour despite the large number of images. We show qualitative examples in Figure 4. We also demonstrate that ACE0 can swiftly optimize an initial set of approximate poses. When starting from KinectFusion poses, ACE0 increases PSNR significantly in less than 10 minutes per scene. In the supplement, we include a parameter study on 7-Scenes to show that ACE0 is robust to the choice of depth estimator. We also show the positive impact of pose refinement on the reconstruction quality as well as the reconstruction speedup due to our early stopping schedule.
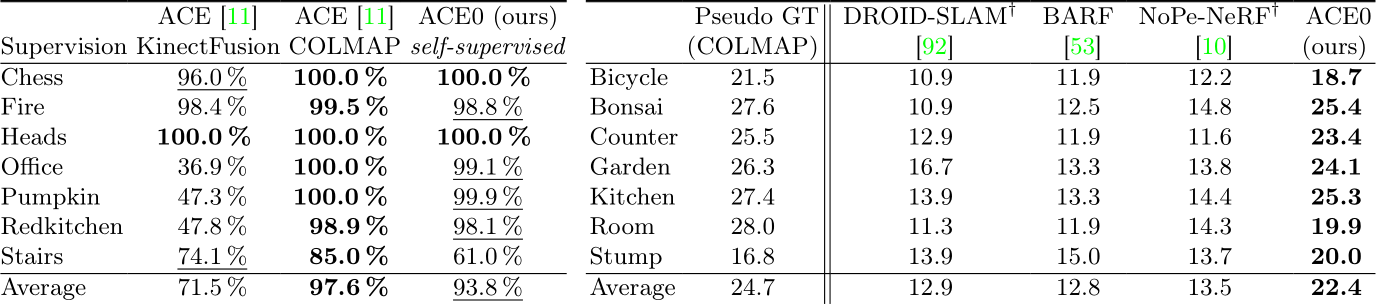
Table 2 (a): Relocalization on 7-Scenes. % poses below 5cm, 5 computed w.r.t. COLMAP pseudo GT.
computed w.r.t. COLMAP pseudo GT.
Table 2 (b): Mip-NeRF 360. Pose quality in PSNR, higher is better. Best in 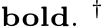 Method needs sequential inputs.
Method needs sequential inputs.
For our learning-based competitors, we sub-sampled images due to their computational constrains, see right side of Table 1. Even using only 200 images, NoPe-NeRF [10] takes 2 days to fit a model and estimate poses. Despite these long processing times, we observe poor pose quality of BARF and NoPe-NeRF in terms of PSNR. BARF [53] requires pose initialisation. We provide identity poses since the scenes of 7Scenes are roughly forward-facing. Still, the camera motions are too complex for BARF to handle. NoPe-NeRF does not require pose initialisation but needs roughly sequential images, which we did provide. NoPeNeRF relies upon successive images having similar poses to perform well, and struggles with the large jumps between the subsampled images.
For the comparison with DUSt3R [98], we had to subsample the sequences further, as we were only able to run it with 50 images at most, even when using an A100 GPU with 40GB memory. DUSt3R achieves reasonable PSNR numbers but consistently lower than ACE0. Relocalization. ACE0 is a learning-based SfM tool but it is also a self-supervised visual relocaliser. In Table 2 (a), we compare it to the supervised relocalizer ACE [11]. Using the scale-metric pseudo ground truth of [12], we train ACE with COLMAP mapping poses, and evaluate it against COLMAP query poses. Unsurprisingly, ACE achieves almost perfect relocalization under the usual 5cm, 5![]() error threshold. Interestingly, ACE0 achieves almost identical results when mapping the scene self-supervised, and evaluating the relocalized query poses against the COLMAP pseudo ground truth. For context, when training ACE with KinectFusion mapping poses and evaluating against COLMAP pseudo ground truth, results are far worse. This signifies that ACE0 mapping poses are very similar to the COLMAP mapping poses, and less similar to KinectFusion mapping poses. We give more details about this experiment in the supplement.
error threshold. Interestingly, ACE0 achieves almost identical results when mapping the scene self-supervised, and evaluating the relocalized query poses against the COLMAP pseudo ground truth. For context, when training ACE with KinectFusion mapping poses and evaluating against COLMAP pseudo ground truth, results are far worse. This signifies that ACE0 mapping poses are very similar to the COLMAP mapping poses, and less similar to KinectFusion mapping poses. We give more details about this experiment in the supplement.
4.2 Mip-NeRF 360
The Mip-NeRF 360 dataset [5] consists of seven small-scale scenes, both indoor and outdoor. The dataset was reconstructed with COLMAP and comes with intrinsics (which we ignore), camera poses and undistorted (pinhole camera) images. For each method, we assume a shared focal length per scene.
Discussion. We present PSNR results in Table 2 (b). NoPe-NeRF does not perform well on this dataset, even after processing each scene for 2 days on av-
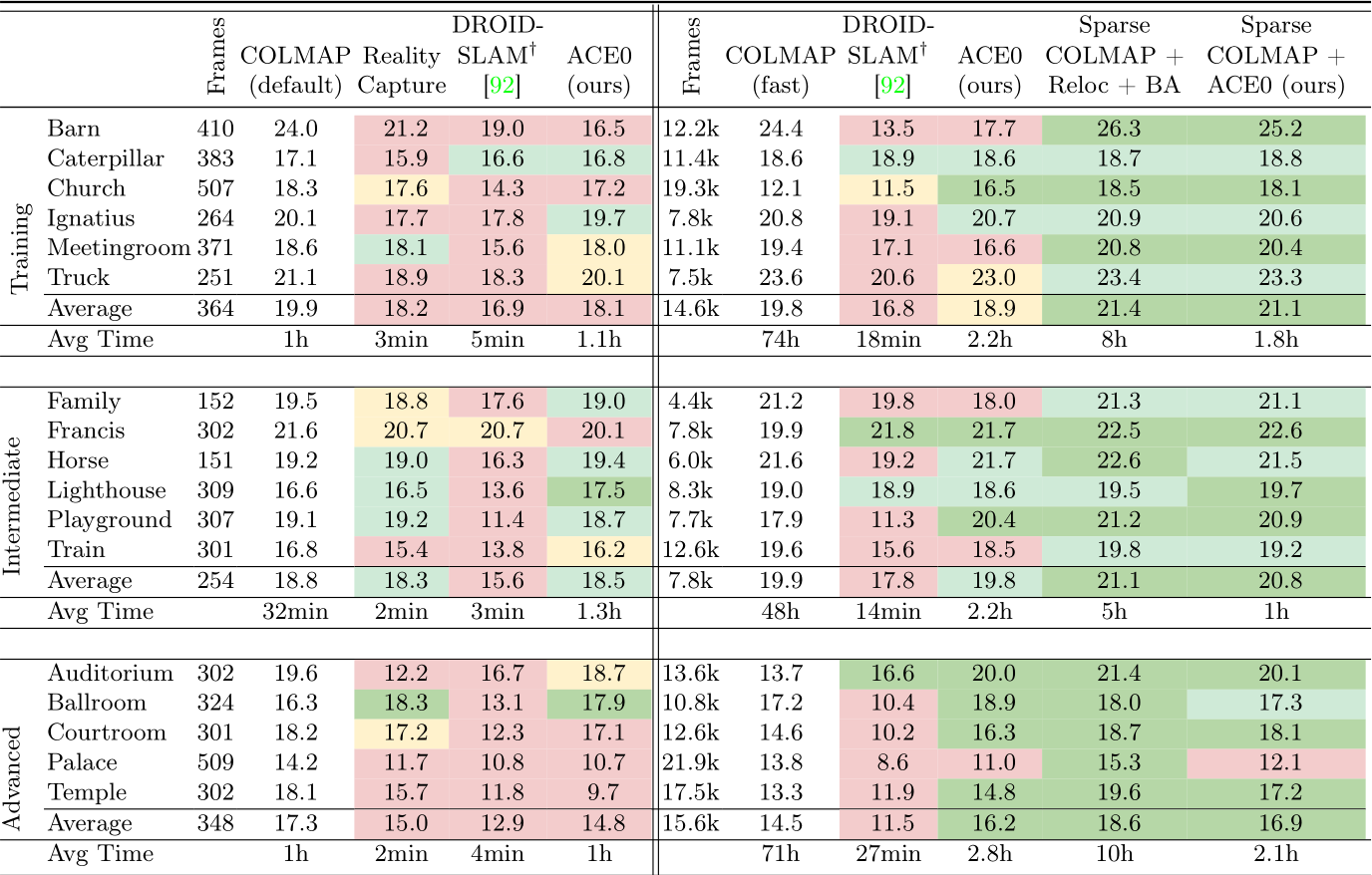
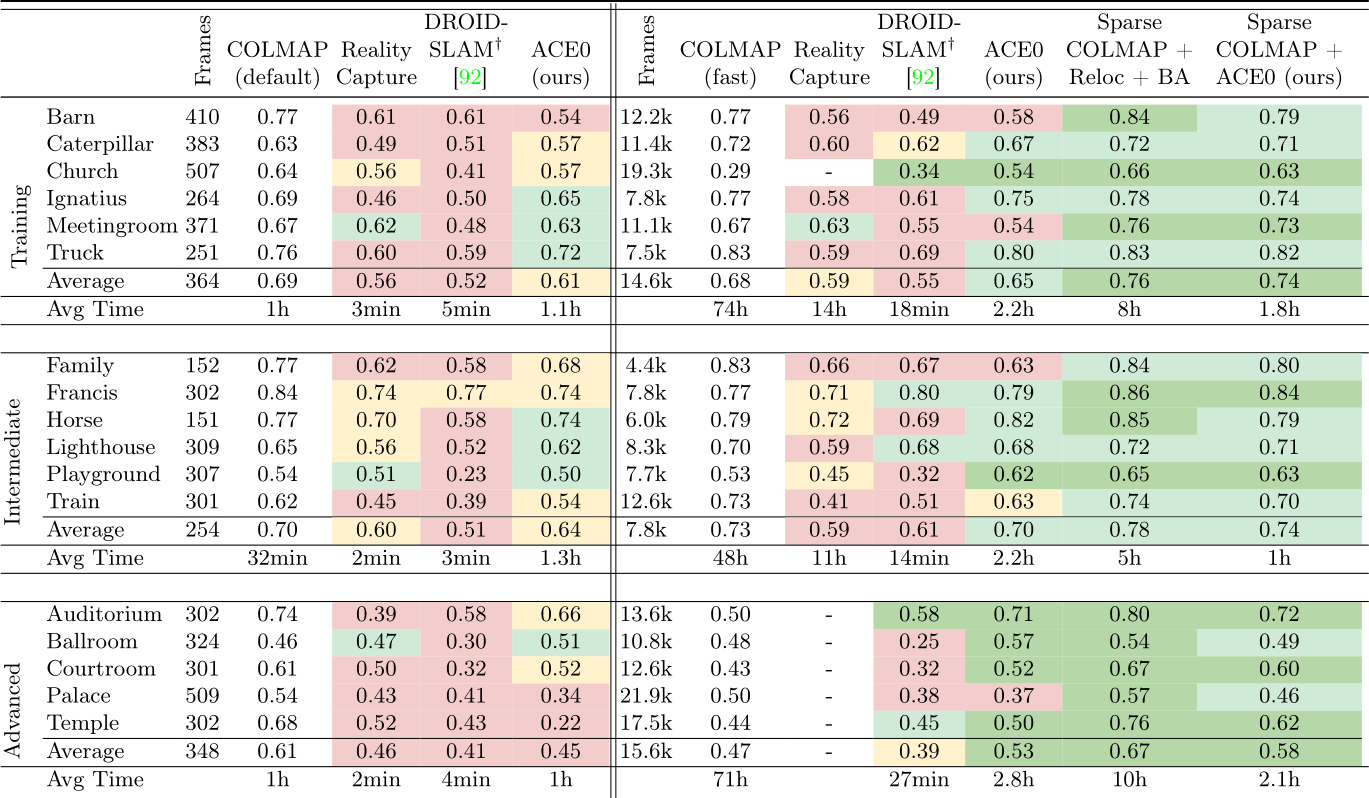
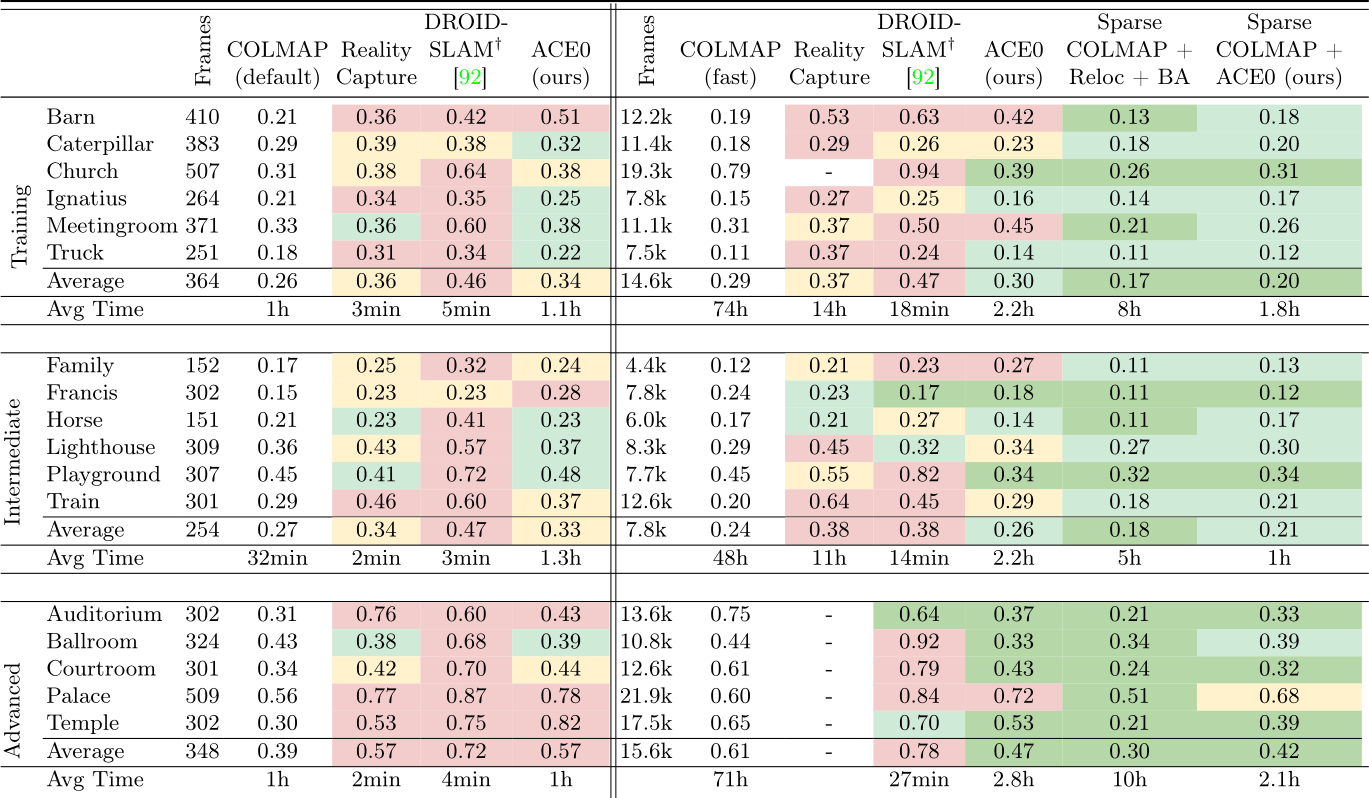
Table 3: Tanks and Temples. We show the pose accuracy via view synthesis with Nerfacto [91] as PSNR in dB, and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.5 dB better within ![]() 1 dB worse .
1 dB worse .  quential inputs.
quential inputs.
erage. The differences between sequential images are too large. DROID-SLAM fails for the same reason. BARF performs poorly because the identity pose is not a reasonable initialisation for most scenes in this dataset. In contrast, ACE0 reconstructs the dataset successfully. While it achieves slightly lower PSNR than COLMAP, we find its pose estimates to be similar, cf . Figure 4 and the supplement.
4.3 Tanks and Temples
The Tanks and Temples dataset [48] contains 21 diverse scenes, both indoors and outdoors, and with varying spatial extent. We remove two scenes (Panther, M60) with military associations. We also remove two scenes (Courthouse, Museum) where the COLMAP baseline did not finish the reconstruction after 5 days of processing or ran out of memory. For the latter two scenes, we provide ACE0 results in the supplement. The dataset provides 150-500 images per scene but also the original videos as a source for more frames. Thus, we consider each scene in two versions: Using 150-500 images and using 4k-22k frames. For all methods, we assume a pinhole camera model with shared focal length across images, and images to be unordered. We found none of the learning-based SfM competitors
to be applicable to this dataset. NoPe-NeRF would run multiple days per scene, even when considering only a few hundred images. DUSt3R would run out of memory. BARF needs reasonable pose initializations which are not available. Discussion. We show PSNR numbers of RealityCapture, DROID-SLAM and ACE0 in Table 3, color-coded by similarity to the COLMAP pseudo GT. ACE0 achieves reasonable results when reconstructing scenes from a few hundred images (Table 3, left). ACE0 generally predicts plausible poses (cf ., Figure 4), even if PSNR numbers are sometimes lower than those of COLMAP. RealityCapture performs similar to ACE0 while DROID-SLAM struggles on the sparse images.
Next, we consider more than 1k images per scene (right side of Table 3). Here, we run COLMAP with parameters tuned for large images collections (fast) due to the extremely large image sets. ACE0 offers a reconstruction quality comparable to COLMAP on average while also being fast. RealityCapture produced fractured reconstructions when applied to these large images sets. We show some of its results in the supplement. DROID-SLAM still struggles on many scenes despite having access to sequential images that are temporally close.
In the two rightmost columns, we initialise with a sparse COLMAP reconstruction from 150-500 images, and extend and refine it using all available frames. Firstly, using a feature-based baseline, we register the full set of frames using the relocalization mode of COLMAP, followed by a final round of bundle adjustment. Secondly, we run ACE0 initialised with the poses of the sparse COLMAP reconstruction. Both variants are considerably faster than running COLMAP from scratch on the full set of frames. ACE0 is able to register and refine all additional frames in 1-2 hours, on average. Again, we find the pose quality of ACE0 comparable to the feature-based alternative.
We have presented scene coordinate reconstruction, a new approach to learning-based structure-from-motion built on top of scene coordinate regression. We learn an implicit, neural scene representation from a set of unposed images. Our method, ACE0, is able to reconstruct a wide variety of scenes. In many cases, the accuracy of estimated poses is comparable to that of COLMAP. Unlike previous learning-based SfM methods, ACE0 can be applied to sets of multiple thousand unsorted images, without pose priors, and reconstructs them within a few hours. Limitations. We show some failure cases in the supplement. Scene coordinate regression struggles with repetitive structures since the network is not able to make multi-modal predictions for visually ambiguous inputs. Scene coordinate regression struggles with representing large areas. The common solution is to use network ensembles based on pre-clustering of the scene [11,15]. However, in a reconstruction setting, networks would have to be spawned on the fly as the reconstruction grows. In our experiments we assumed a simple pinhole camera model. To the best of our knowledge, scene coordinate regression has not been coupled with image distortion, thus far.
Reconstruction Loop. We start the reconstruction as explained in Section 3.3 of the main paper. We repeat neural mapping and registration of new views until all views have been registered, or less than 1% of additional views are registered compared to the last relocalization stage. In each relocalization iteration, we re-estimate the poses of all views, even if they have been registered before. This gives the pipeline the ability to correct previous outlier estimates. We consider an image to be registered successfully, if it has at least 500 inlier correspondences with an inlier threshold of 10px. At the end of the reconstruction, we apply a more conservative threshold of 1000 inliers to make sure only high quality poses are kept. For each neural mapping iteration, we load the network weights of the scene coordinate regression network of the previous mapping iteration and refine further. We conclude the reconstruction loop with a final refit of the model, using the standard ACE training parameters. In this last iteration, we start with a randomly initialised network, rather than loading previous weights.
Neural Mapping. The ACE backbone predicts 512-dimensional features densely for the input image, but sub-sampled by a factor of 8. Training images are augmented using random scaling and rotation as well as brightness and contrast changes as in ACE [11]. When filling the training buffer, we randomly choose 1024 features per training image, and we sample features from each training image at most 10 times, i.e. for 10 different augmentations. During training, we use a batch size of 5120 features. Our pose refinement MLP has 6 layers with 128 channels and a skip connection between layer 1 and 3. We optimize the pose refinement MLP, and the relative scaling factor for the focal length, with separate AdamW [57] instances and a learning rate of  . In the seed iteration, we optimize neither the seed pose (which is identity) nor the initial calibration parameters.
. In the seed iteration, we optimize neither the seed pose (which is identity) nor the initial calibration parameters.
ACE uses a soft-clamped version of the reprojection error in Eq. 3 (main paper) with a soft threshold that reduces from 50px to 1px throughout training. We use the same, soft-clamped loss but keep the threshold fixed at 50px as we saw no benefit when using the loss schedule but it complicates early stopping. During the seed iteration, we switch from optimizing the Euclidean distance to optimizing the reprojection error if the reprojection error of a scene coordinate is lower than 10px. This hybrid objective is inspired by the RGB-D version of DSAC* [16].
When starting neural mapping from a set of initial poses, e.g. from KinectFusion, a sparse COLMAP reconstruction or in the final model refit of the reconstruction loop, we keep the pose refinement MLP frozen for the first 5000 iterations. The refinement MLP cannot predict sensible updates for an uninitialised scene representation, and the reconstruction would become unstable. Note that this standby time is not required in all but the last training itera- tion, as we initialise the scene coordinate regressor using the weights of the last iteration, so the pose refiner can predict sensible updates right away.
Relocalisation. For registering images to the scene reconstruction, we utilize the pose optimization of ACE [11]. It consists of a PnP solver within a RANSAC loop. ACE samples 64 pose hypotheses per image. If sampling a hypothesis fails, ACE tries again, up to 1M times. After sampling, ACE ranks hypotheses according to inlier counts using a reprojection error threshold of 10px. The best hypothesis is refined by iteratively resolving PnP on the growing inlier set.
Usually, this procedure is fast, taking approximately 30ms per image. However, when the predicted image-to-scene correspondences are bad, sampling hypothesis can take a long time due to the large number of re-tries. For ACE0, this will happen often, namely when we try to register images that are not yet covered by the reconstruction. Thus, we decrease the number of re-tries to from 1M to 16. When registering images throughout the reconstruction, we also decrease the number of hypotheses drawn from 64 to 32. This yields registration times of 20ms per image, irrespective of whether the registration succeeds or fails.
We benchmark the quality of each set of poses by training a NeRF model on the train views and evaluating on the test views. We use Nerfstudio’s Nerfacto model for this [91]. Where datasets already include a train/test split – as in 7-Scenes – we use that split. Where a dataset does not already include a train/test split, we take every eighth view as a test view, which is a common choice for many NeRF datasets.
Many scenes in this work have large test sets of several thousand images or more. This can lead to long evaluation times due to the cost of rendering thousands of test views with NeRF – much longer than the time to fit the NeRF itself. For this reason we subsample very large test sets so that they contain no more than 2k views. To ensure that this reduced test set is representative, we do this by subsampling evenly throughout the full-size test set in a deterministic manner. The code to compute the resulting splits will be included in our code release.
We use Nerfacto’s default normalization of poses to fit into a unit cube, and enable scene contraction so that distant elements of the scene can be modelled more accurately. We train each scene for 30k iterations. For NeRF training and evaluation we downscale the resolution so that the longest side of an image is not greater than 640 pixels, as NeRFs often perform poorly with high-resolution training images.
Where a pose for a test view is not provided by a given method, we use the identity pose for that view. This results in a very low PSNR for that image, penalising the method for its failure to provide a pose. This means that we evaluate all methods on the full set of test views, even where they do not provide poses for all such views. If a reconstruction results in multiple disconnected components, we use the largest component in our benchmark and consider the other frames as missing. This happens rarely for COLMAP, but more often for RealityCapture (c.f. Sec. D).
ACE0 pose estimates are generally available for all images, but we consider an image registered if its confidence exceeds the threshold of 1000 inliers. However, when evaluating test images we always take the estimated pose instead of the identity pose as basis for the evaluation, even if the confidence is lower than 1000. Note that the question of whether a frame is considered “registered” or not is still important when fitting the NeRF, as such images are excluded from NeRF training. See Sec. C for further information about registration rates for different methods.
Relocalization. In the following, we give more information about the relocalization experiment of Section 4.1 and Table 2 (a) of the main paper. We conducted the experiment on the 7-Scenes dataset adhering to its training / test split. Our experiments utilize the pseudo ground truth (pGT) poses of KinectFusion that come with the dataset, as well as the COLMAP pGT of [12]. The authors of [12] obtained the COLMAP pGT by reconstructing the training images of each scene with COLMAP from scratch. To make the pGT scale-metric, they aligned the COLMAP reconstruction with the KinectFusion poses. To obtain poses for the test images of each scene as well, they registered the test images to the training reconstruction. Lastly, they ran a final round of bundle adjustment to refine the test poses while keeping the training poses fixed.
In our experiment, we train the ACE relocalizer on the training images of each scene. Firstly, we train ACE using the KinectFusion poses that come with the dataset. Secondly, we train ACE using the COLMAP pGT of [12]. We evaluate both version of the relocaliser using the COLMAP pGT. As expected, ACE trained with KinectFusion poses scores lower than ACE trained with COLMAP pGT, when evaluating against COLMAP pGT. This confirms the finding of [12] that KinectFusion and COLMAP produce different pose estimates.
Next, we run ACE0 on the training set of each scene to reconstruct it and estimate the training poses. One output of ACE0 is an ACE relocalizer, trained from scratch without poses, in a self-supervised fashion. We apply the ACE0 relocalizer to the test images to estimate their poses - without any further model refinement or joint optimization. The ACE0 reconstruction is scale-less, or only roughly scaled based on the ZoeDepth estimate of the seed image. To enable the scale-metric evaluation of Table 2 (a) of the main paper, we align the ACE0 pose estimates to the test pseudo ground truth by fitting a similarity transform. Specifically, we run RANSAC [33] with a Kabsch [45] solver on the estimated and the ground truth camera positions with 1000 iterations. Due to the optimization of the similarity transform, we might underestimate the true relocalization error. For a fair comparison, we perform the exact same evaluation procedure for our ACE baselines and fit a similarity transform although they have already been trained with scale-metric poses. The effect of fitting the similarity transform is small. ACE, trained on COLMAP pGT, achieves 97.1% average relocalization accuracy when we fit the similarity transform, and 97.6% average accuracy without fitting the transform. We compute accuracy as the percentage of test images where the pose error is smaller than 5cm and 5![]() compared to ground truth. The ACE0 relocalizer achieves 93.8% average accuracy when evaluated against the COLMAP pGT. The accuracy differences are smaller than 1% for all scenes except Stairs. This experiment shows that ACE0 is a viable self-supervised relocalizer, and that ACE0 poses are very close to COLMAP poses up to a similarity transform - much closer than e.g. KinectFusion poses are to COLMAP poses.
compared to ground truth. The ACE0 relocalizer achieves 93.8% average accuracy when evaluated against the COLMAP pGT. The accuracy differences are smaller than 1% for all scenes except Stairs. This experiment shows that ACE0 is a viable self-supervised relocalizer, and that ACE0 poses are very close to COLMAP poses up to a similarity transform - much closer than e.g. KinectFusion poses are to COLMAP poses.
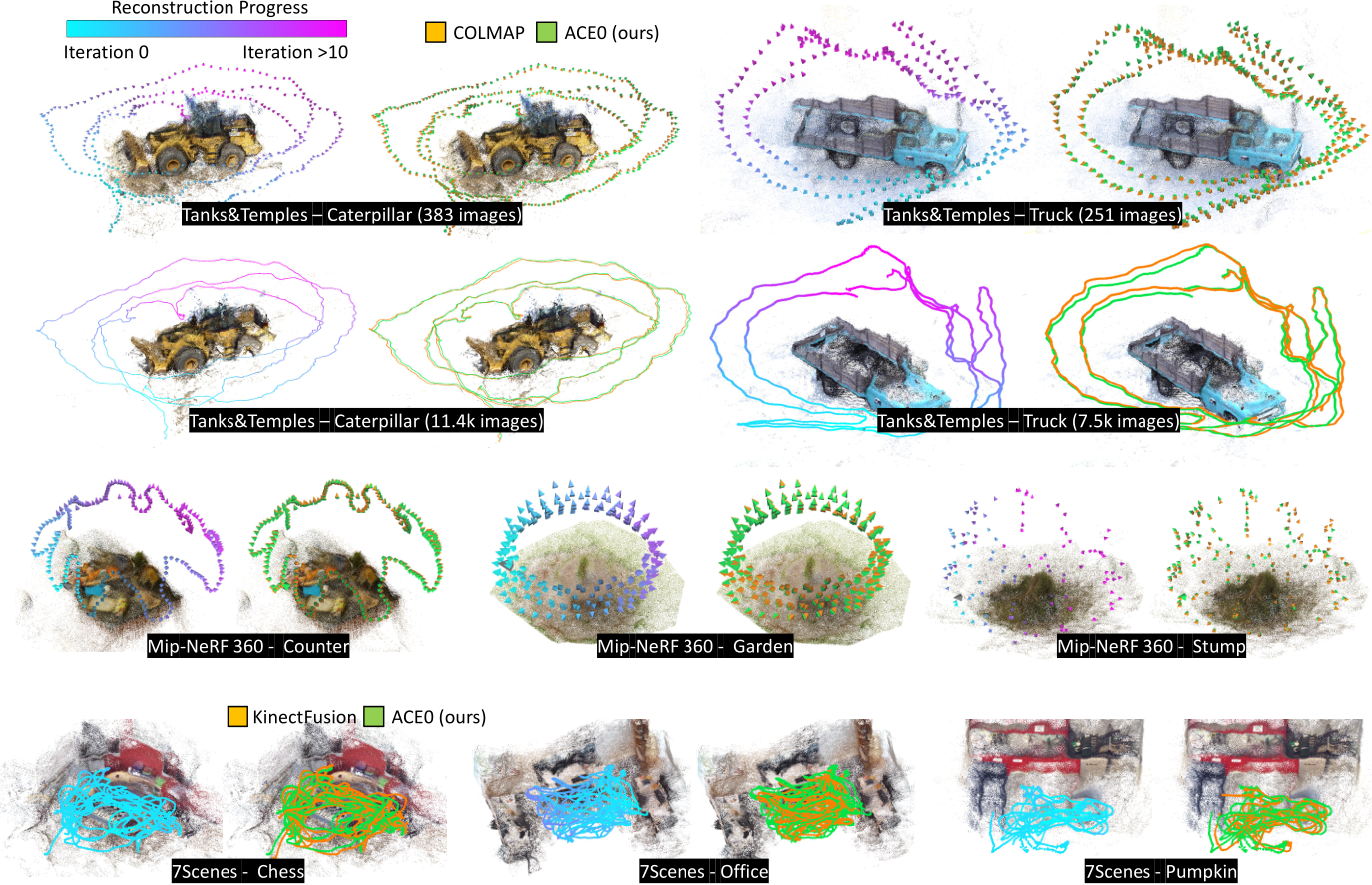
Fig. 5: More Reconstructed Poses. We show poses estimated by ACE0. We color code the reconstruction iteration in which a particular view has been registered. We show the ACE0 point cloud as a representation of the scene. We also compare our poses to poses estimated by COLMAP (Mip-NeRF 360, Tanks and Temples) and KinectFusion (7-Scenes).
More Qualitative Results. We show qualitative results in terms of estimated poses for more scenes in Fig. 5. We show failure cases in Fig. 6 corresponding to some of the limitations discussed in Section 5 of the main paper.
Additionally, we show synthesized views based on ACE0 poses. Corresponding to our quantitative results in the main paper (Table 1, Table 2 (b), Table 3 of the main paper), we select one test image per scene that is representative of

Fig. 6: Failure Cases. Stairs: Parts of the reconstruction collapse due to visual ambiguity. Room: ACE0 fails to register the views on the right due to low visual overlap. Courthouse is too large to be represented well by a single MLP.
the view synthesis quality of ACE0 on that scene. More specifically, we select the test image where ACE0 achieves its median PSNR value. For comparison, we synthesise the same image using the estimated poses of our competitors. For synthesised images of 7-Scenes, see Fig. 7. For comparison with BARF and NoPe-NeRF, the main paper reports results on a 200 image subset per scene. We show the associated synthesized images in Fig. 8. For comparison with DUSt3R, the main paper reports results on a 50 image subset per scene. We show the associated synthesized images in Fig. 9. We show synthesized images for the MIP-NeRF 360 dataset in Fig. 10. We also show synthesized images for Tanks and Temples, in Fig. 11 for Training scenes, in Fig. 12 for Intermediate scenes, and in Fig. 13 for Advanced scenes.
More Quantitative Results. For completeness, we augment Table 1 in the main paper with SSIM [99] and LPIPS [106] scores for the 7-Scenes dataset, c.f., Tables 4 and 5 respectively. Similarly, Tables 13 and 14 show SSIM [99] and LPIPS [106] scores for the Tanks and Temples dataset, augmenting Table 3 in the main paper. Furthermore, Tables 15 and 16 show SSIM [99] and LPIPS [106] scores for the Mip-NeRF 360 dataset, augmenting Table 2 (b) in the main paper. In all cases, SSIM and LPIPS behave very similar to PSNR in our experiments, and support the conclusions of the main paper.
Analysis. We show variations of ACE0 in Table 6 alongside PSNR numbers and reconstruction times for 7-Scenes.
ACE0 picks 5 random seed images to start the reconstruction. We show average statistics of ACE0 over five runs, starting off with different sets of seed images each time. The standard deviation is low with 0.2 dB in PSNR, and about 4 minutes in terms of reconstruction time.
We pair ACE0 with different depth estimators, namely ZoeDepth [7] and PlaneRCNN [56] but observe only small differences. The depth estimates are only used for the seed iteration, and their impact fades throughout the reconstruction process. Indeed, using ground truth depth, measured by a Kinect sensor, yields no noteworthy advantage either.
We run a version of ACE0 that ingests ZoeDepth estimates for all frames and uses them in all reconstruction iterations. Thus, rather than optimizing the reprojection error of Eq. 3 of the main paper, we optimize the Euclidean distance
![]() We show the pose accuracy via view synthesis with Nerfacto [91] as
We show the pose accuracy via view synthesis with Nerfacto [91] as ![]() ], and the reconstruction time. Results for All Frames are color coded w.r.t. similarity to the COLMAP pseudo ground truth: > 0.05 better , within
], and the reconstruction time. Results for All Frames are color coded w.r.t. similarity to the COLMAP pseudo ground truth: > 0.05 better , within ![]() worse . For some competitors, we had to sub-sample the images due to their computational complexity (right side).
worse . For some competitors, we had to sub-sample the images due to their computational complexity (right side). ![]() Method needs sequential inputs.
Method needs sequential inputs. ![]() Results on more powerful hardware.
Results on more powerful hardware.
![]() We show the pose accuracy via view synthesis with Nerfacto [91] as
We show the pose accuracy via view synthesis with Nerfacto [91] as ![]() ], and the reconstruction time. Results for All Frames are color coded w.r.t. similarity to the COLMAP pseudo ground truth: > 0.05 better (lower) , within
], and the reconstruction time. Results for All Frames are color coded w.r.t. similarity to the COLMAP pseudo ground truth: > 0.05 better (lower) , within ![]() worse (higher) , > 0.1 worse (higher) . For some competitors, we had to sub-sample the images due to their computational complexity (right side).
worse (higher) , > 0.1 worse (higher) . For some competitors, we had to sub-sample the images due to their computational complexity (right side). ![]() Method needs sequential inputs.
Method needs sequential inputs. ![]() Results on more powerful hardware.
Results on more powerful hardware.

Fig. 7: View Synthesis Quality on 7-Scenes. For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). These results correspond to Table 1 of the main paper.

Fig. 8: View Synthesis Quality on 7-Scenes (200 Images Subset). For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). For all methods, we obtain these results on a subset of 200 images per scene to achieve a reasonable training time of NoPe-NeRF. These results correspond to Table 1(right) of the main paper.

Fig. 9: View Synthesis Quality on 7-Scenes (50 Images Subset). For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). For all methods, we obtain these results on a subset of 50 images per scene to prevent DUSt3R from running out of GPU memory. These results correspond to Table 1(right) of the main paper.

Fig. 10: View Synthesis Quality on the MIP-NeRF 360 dataset. For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). These results correspond to Table 2 (b) of the main paper.
to pseudo ground truth scene coordinates computed from depth estimates. Accuracy is slightly lower, and reconstruction times longer. The depth estimates are not multi-view consistent, and the model has problems to converge.
Omitting pose refinement during neural mapping leads to a drop in PSNR of more than 2 dB. Refinement via an MLP that predicts updates has a small but noticeable advantage over direct optimization of poses via back-propagation.
Finally, PNSR numbers with early stopping are similar to using the static ACE training schedule, but reconstruction times are shorter.
More Scenes. As mentioned in the main paper, we removed two scenes from the Tanks and Temples dataset because the COLMAP baseline was not able to reconstruct them after days of processing or ran out of memory. This concerns the Courthouse and the Museum scenes in the variation with 4k frames and more. In Table 7 we show ACE0 results for these two scenes, COLMAP results when using only a few hundred images, as well as other baselines.
Registration Rates. Reconstruction algorithms do not always succeed in registering all input frames to the reconstruction. While high registration rates are

Fig. 11: View Synthesis Quality on Tanks and Temples (Training Scenes). For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). These results correspond to Table 3 of the main paper. Top: Results based on 150-500 images per scenes. Bottom: Results based on 4k-22k frames sampled from the full video.

Fig. 12: View Synthesis Quality on Tanks and Temples (Intermediate Scenes). For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). These results correspond to Table 3 of the main paper. Top: Results based on 150-500 images per scenes. Bottom: Results based on 4k-22k frames sampled from the full video.

Fig. 13: View Synthesis Quality on Tanks and Temples (Advanced Scenes). For each scene, we show the test image where ACE0 achieves its median PSNR value. For comparison, we show the corresponding results of our baselines as well as the true test image (GT). These results correspond to Table 3 of the main paper. Top: Results based on 150-500 images per scenes. Bottom: Results based on 4k-22k frames sampled from the full video.
in general desirable, it is also disadvantageous to register images incorrectly. Clearly, an algorithm that always returns the identity pose has a 100% registration rate but is not very useful. Therefore, in our main experimental results, we compare algorithms based on PSNR numbers rather than registration rates. The way we calculate PSNR numbers punishes an algorithm for any incorrect estimate whether its considered “registered” or not, see Sec. B for details. Nevertheless, we provide registration rates of ACE0 and COLMAP in Tables 8 and 9. Both algorithms achieve high registration rates for many scenes. Scenes with low registration rates also show low PSNR numbers in our main experimental results.
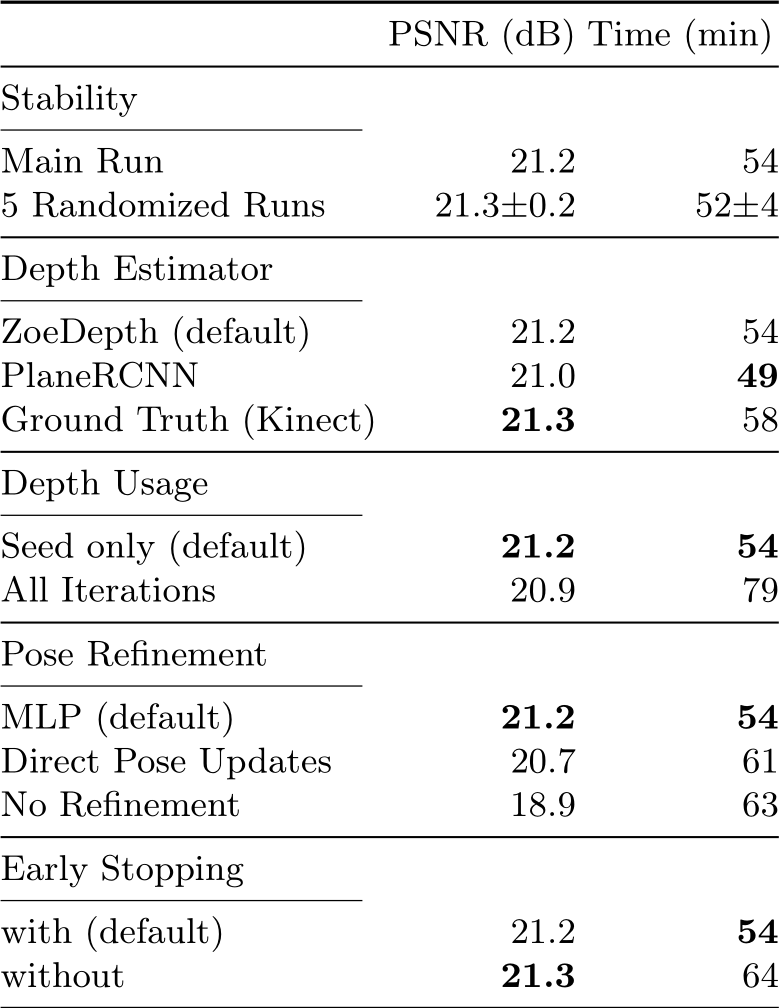
Table 6: ACE0 Variations. We demonstrate the impact of various design and parameter choices as PSNR in dB and reconstruction time in minutes, on 7-Scenes.
COLMAP. We run COLMAP in three variations: Default, fast, and “Sparse COLMAP + Reloc + BA”. Fast uses parameters recommended for large image collections beyond 1000 images [81]. “Sparse COLMAP + Reloc + BA” uses default parameters to obtain the initial reconstruction, and fast parameters to register the remaining frames. We provide the parameters of the mapper of the
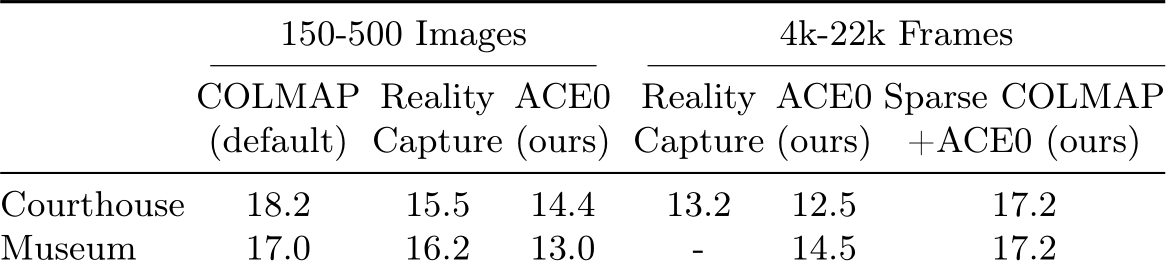
Table 7: Additional ACE0 Results. We provide results for two additional scenes of Tanks and Temples where the COLMAP baseline did not finish the reconstruction (with 4k+ frames) after running for more than 5 days or ran out of memory.
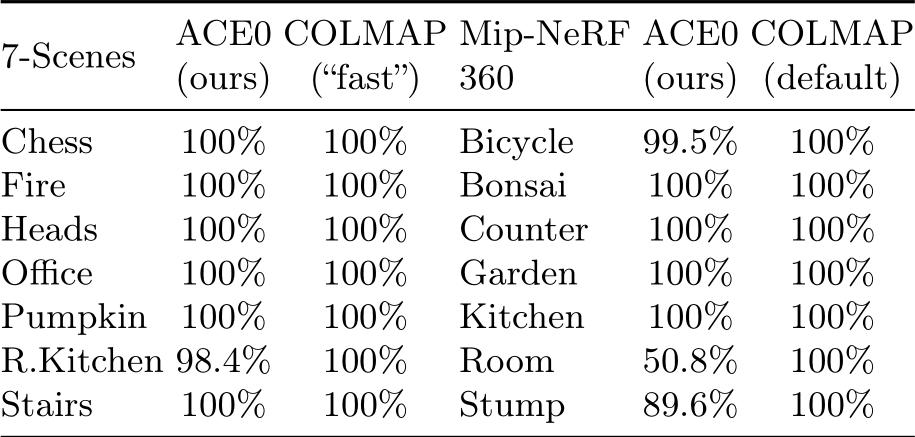
Table 8: Registration Rates on 7-Scenes and Mip-NeRF 360. We show the percentage of registered images for ACE0 and COLMAP. Note that the way we calculate PSNR numbers already accounts for registration rates below 100%.
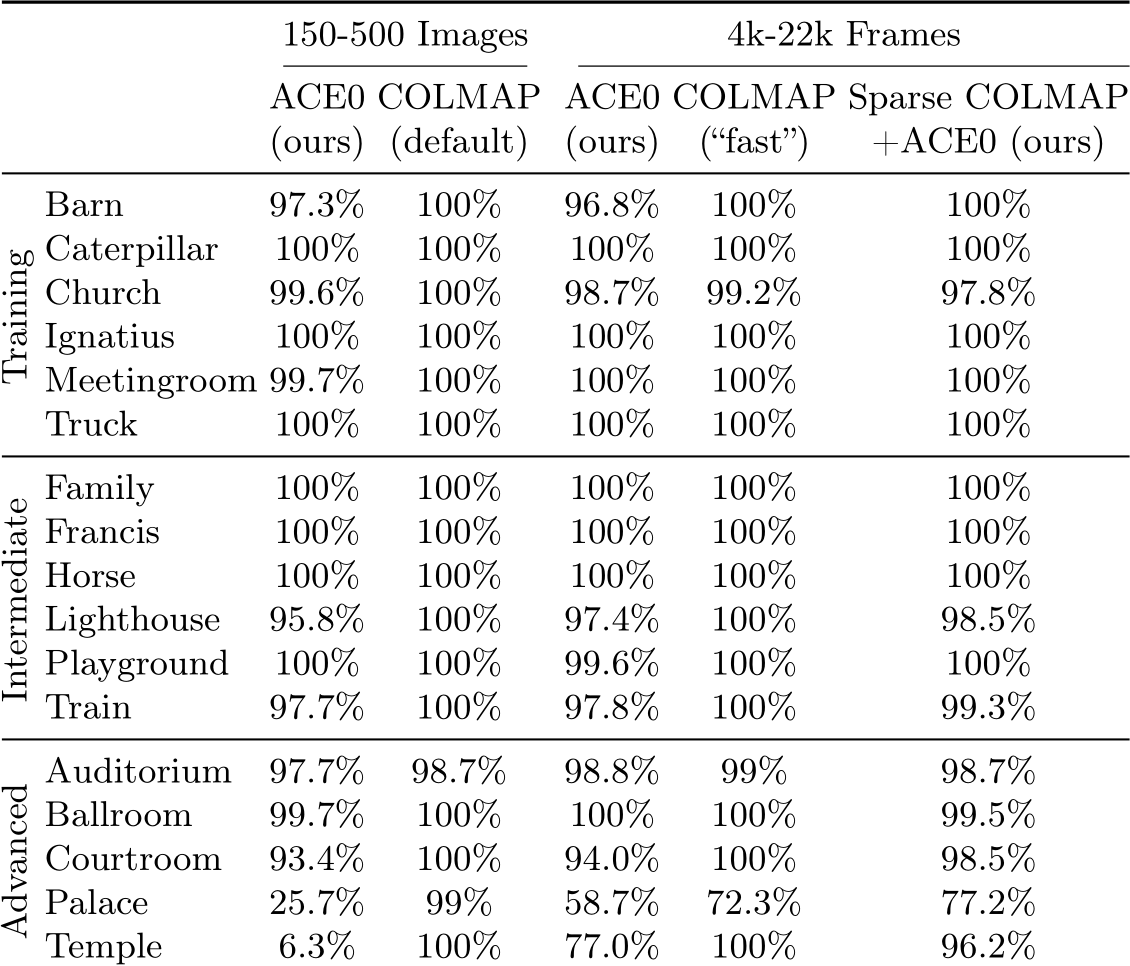
Table 9: Registration Rates on Tanks and Temples. We show the percentage of registered images for ACE0, COLMAP, and the combination of ACE0 and COLMAP. Note that the way we calculate PSNR numbers already accounts for registration rates below 100%.
default variation in Table 17. For the fast version, we provide the parameters that have been changed compared to default in Table 18. We also include the parameters of the feature extractor and the matcher shared by both variations in Tables 19 and 20.
As additional comparison to further optimize for efficiency, for the Tanks and Temples dataset we also computed in the second to last column of Tables 12 to 14 a COLMAP variant “Sparse COLMAP + Reloc + BA”. As presented at the end of Section 4.3 in the main paper, this variant builds on the sparse reconstruction results, and performs the following steps:
1. (Custom database surgery to prefix the old image names from the “Sparse COLMAP” model to avoid name clashes.)
2. Feature extraction (colmap feature_extractor ...) of the new images using the same parameters as COLMAP default and fast, cf ., Table 19.
3. Vocabulary tree matching (colmap vocab_tree_matcher) of the new images to the old images and each other, using the same parameters as COLMAP default and fast, cf ., Table 20.
4. Image registration (colmap image_registrator ...) of the new images to the old images and each other, given the matches computed in the previous step. The parameters for this step (cf ., Table 21) were set to match the mapper parameters used in COLMAP fast, (cf ., Table 18).
5. A final BA step (colmap bundle_adjuster ...) to refine the poses of the whole scene. Parameters were set similarly to COLMAP fast, cf ., Table 22.
Note, such an algorithm heavily relies on the fact, that the sparse set of images has been selected so that it represents the entire scene, and would need further iterative optimization for datasets where the spatial distribution of images is not known beforehand (e.g., not sequential data or data without priors from other sensors, such as GPS or WiFi).
NoPe-NeRF. We estimate poses with NoPe-NeRF by using the official code at https://github.com/ActiveVisionLab/nope-nerf. We modify the code to ingest both training and test views, since we aim at estimating the poses of all images jointly.
For Mip-NeRF 360 scenes, we use all images per each scene reconstruction. As NoPe-NeRF assumes ordered image sequence, we sorted the images by name for training.
For 7-Scenes, using all frames is prohibitively expensive. For example, the Chess scene has 6000 frames and the implementation just freezes when using them all. The majority of experiments in the NoPe-NeRF paper were done with a few hundred frames, so we subsampled the 7-Scenes scans to extract a total of 200 frames per each scene.
DUSt3R. We follow the official code at https://github.com/naver/dust3r to reconstruct scenes within the 7-scene dataset from uncalibrated and unposed cameras. The DUSt3R framework cannot process all available images of a scene due to GPU memory constraints. By following the guidelines from the official repository, we configured the system to utilize a sliding window approach (w=3), enabling the accommodation of 50 frames within the 16GB memory capacity of a NVIDIA![]() V100 [66] GPU. As a second version, we attempted to reconstruct 50 frames using a NVIDIA
V100 [66] GPU. As a second version, we attempted to reconstruct 50 frames using a NVIDIA![]() A100-40GB GPU in conjunction with the leaner 224x224 pre-trained model and an exhaustive matching configuration. We were not able to pair the full 512x512 model with exhaustive matching, even on a A100-40GB. Of the two configurations that fit into memory, the second one yields the most accurate poses under our experimental settings. Thus, we report the superior results in Table 1 of our main paper. For further insight, we have compiled the experimental statistics in Table 10.
A100-40GB GPU in conjunction with the leaner 224x224 pre-trained model and an exhaustive matching configuration. We were not able to pair the full 512x512 model with exhaustive matching, even on a A100-40GB. Of the two configurations that fit into memory, the second one yields the most accurate poses under our experimental settings. Thus, we report the superior results in Table 1 of our main paper. For further insight, we have compiled the experimental statistics in Table 10.
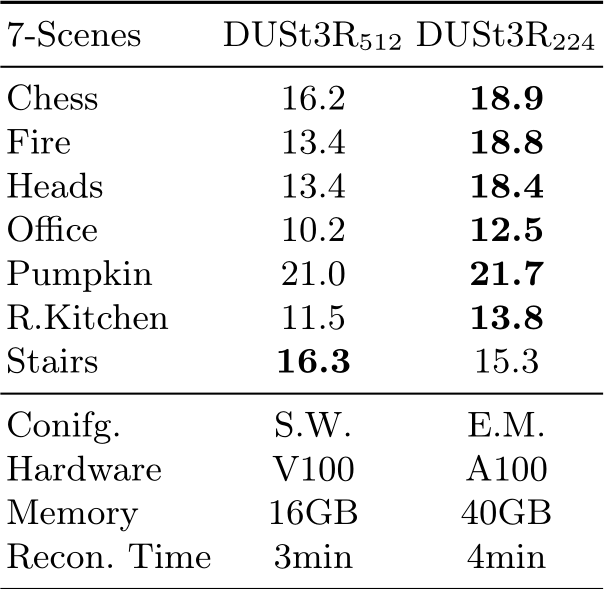
Table 10: DUSt3R on 7-Scenes S.W. denotes the sliding window configuration (window=3). E.M. denotes the exhaustive matching configuration. The performance is evaluated in PSNR (dB) using the same experiments described in Section 4.1 of the main paper. In the bottom part of the table, we show the configuration, GPU hardware, GPU memory, and reconstruction time for 50 frames on each scene.
DROID-SLAM. We estimated poses for the 7-Scenes (using only the RGB images), Tanks and Temples, and Mip-NeRF 360 datasets using the official code from: https://github.com/princeton-vl/DROID-SLAM. In our experiments we used the same parameters that the DROID-SLAM authors chose to evaluate the method on the ETH-3D dataset and resized the input images to a resolution having an area of ![]() pixels, while preserving the aspect ratio. As the SLAM method requires sequential input, we sorted the images by name, although that does not remove all jumps from the datasets. For example, each scene in the 7-Scenes dataset is composed of a sequence of disjoint scans observing the same area, and the algorithm might have difficulties in tracking accurately around the discontinuities.
pixels, while preserving the aspect ratio. As the SLAM method requires sequential input, we sorted the images by name, although that does not remove all jumps from the datasets. For example, each scene in the 7-Scenes dataset is composed of a sequence of disjoint scans observing the same area, and the algorithm might have difficulties in tracking accurately around the discontinuities.
 We also reconstructed scenes from the Tanks and Temples dataset using Reality Capture
We also reconstructed scenes from the Tanks and Temples dataset using Reality Capture![]() , as discussed in Section 4.3 in the main paper. In Table 12, we extend the results presented in the table in Table 3 in the paper with results for training videos and intermediate videos (third column on the right side). For completeness, we also computed SSIM [99] and LPIPS [106] scores in Tables 13 and 14 respectively. On the sparse images (150-500), Reality Capture performs one order of magnitude faster than COLMAP but with slightly worse pose quality. When we ran it on Tanks and Temples with thousands of frames, Reality Capture produced a high number of disconnected components. We use the largest component as basis for our evaluation and regard all other frames as missing, as described in Appendix B.
, as discussed in Section 4.3 in the main paper. In Table 12, we extend the results presented in the table in Table 3 in the paper with results for training videos and intermediate videos (third column on the right side). For completeness, we also computed SSIM [99] and LPIPS [106] scores in Tables 13 and 14 respectively. On the sparse images (150-500), Reality Capture performs one order of magnitude faster than COLMAP but with slightly worse pose quality. When we ran it on Tanks and Temples with thousands of frames, Reality Capture produced a high number of disconnected components. We use the largest component as basis for our evaluation and regard all other frames as missing, as described in Appendix B.
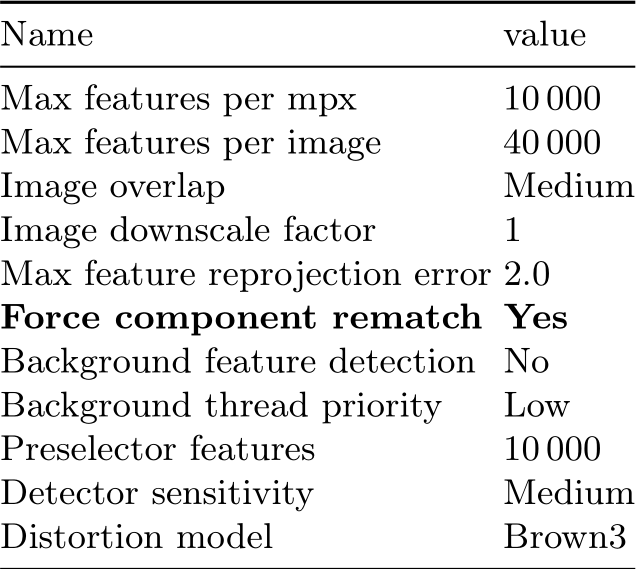
Table 11: Reality Capture alignment settings. We used the default settings for our experiments, except for settings in bold.
We used Reality Capture version 1.3.2.117357 with the default alignment parameters ., Table 11.
., Table 11.
The runtimes in Tables 12 to 14 were measured for the iv) alignment step only, excluding the steps i) starting the software, ii) checking license, iii) importing images from local SSD before, and v) exporting poses as XMP, vi) saving the project to local SSD and vii) closing the software after the iv) alignment step. In order to find a good balance between CPU and GPU compute power, all our Reality Capture experiments were run on cloud machine with 48 logical CPU cores (Intel![]() Skylake, Xeon@2.00 Ghz), a single NVIDIA
Skylake, Xeon@2.00 Ghz), a single NVIDIA![]() T4 [67] GPU and 312GB RAM.
T4 [67] GPU and 312GB RAM.
1. Agarwal, S., Furukawa, Y., Snavely, N., Simon, I., Curless, B., Seitz, S.M., Szeliski, R.: Building Rome in a day. ACM TOG (2011) 3
![]() We show the pose accuracy via view synthesis with Nerfacto [91] as
We show the pose accuracy via view synthesis with Nerfacto [91] as ![]() ) in dB, and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.5 dB better , within
) in dB, and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.5 dB better , within ![]() dB worse , > 1 dB worse .
dB worse , > 1 dB worse . ![]() Method needs sequential inputs.
Method needs sequential inputs.
![]() We show the pose accuracy via view synthesis with Nerfacto [91] as
We show the pose accuracy via view synthesis with Nerfacto [91] as ![]() ], and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.05 better , within
], and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.05 better , within  Method needs sequential inputs.
Method needs sequential inputs.
![]() We show the pose accuracy via view synthesis with Nerfacto [91] as
We show the pose accuracy via view synthesis with Nerfacto [91] as ![]() ], and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.05 better (lower) , within
], and the reconstruction time. We color code results compared to COLMAP, default and fast, respectively: > 0.05 better (lower) , within ![]() worse (higher) , > 0.1 worse (higher) .
worse (higher) , > 0.1 worse (higher) . ![]() Method needs sequential inputs.
Method needs sequential inputs.

![]() Pose quality in
Pose quality in ![]() ], higher is better. Best in
], higher is better. Best in  Method needs sequential inputs.
Method needs sequential inputs.
![]() Pose quality in
Pose quality in ![]() ], lower is better. Best in
], lower is better. Best in 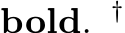 Method needs sequential inputs.
Method needs sequential inputs.
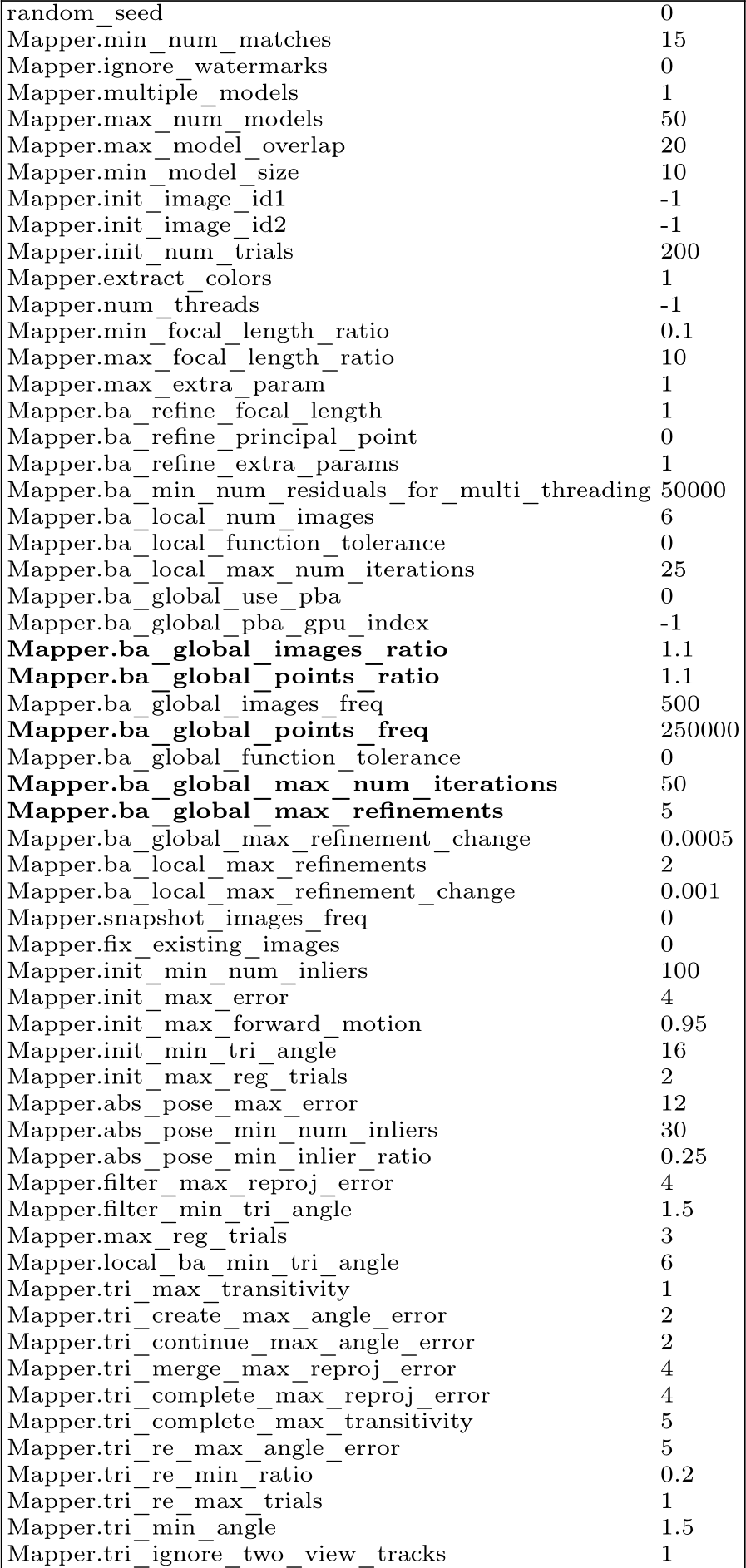
![]() incremental mapper options. Bold denotes options later changed in the fast version, cf ., Table 18.
incremental mapper options. Bold denotes options later changed in the fast version, cf ., Table 18.

Table 18: The incremental mapper options we used when running COLMAP fast. Other parameters were not changed, and can be seen in Table 17. Parameters were recommended for large image collections of more than 1000 images by [81].

![]() denotes options changed w.r.t. default. Ran on an NVIDIA
denotes options changed w.r.t. default. Ran on an NVIDIA![® V100 [66] GPU.](https://cdn.bytez.com/mobilePapers/v2/arxiv/2404.14351/images/36-3.png)

Table 20: COLMAP’s default vocab_tree_matcher options used. Ran on an NVIDIA![® V100 [66] GPU.](https://cdn.bytez.com/mobilePapers/v2/arxiv/2404.14351/images/37-1.png)

Table 21: The image_registrator options used for COLMAP in the “Sparse COLMAP + Reloc + BA” step. Bold denotes options changed w.r.t. default. Parameters set to match Table 18, as recommended for large image collections of more than 1000 images by [81].
![]()
Table 22: The bundle_adjuster options used for COLMAP in the “Sparse COLMAP + Reloc + BA” step. Bold denotes options changed w.r.t. default. Parameters set to match Table 18, as recommended for large image collections of more than 1000 images by [81].
2. Agarwal, S., Snavely, N., Seitz, S.M., Szeliski, R.: Bundle adjustment in the large. In: ECCV (2010) 3
3. Arnold, E., Wynn, J., Vicente, S., Garcia-Hernando, G., Monszpart, A., Prisacariu, V.A., Turmukhambetov, D., Brachmann, E.: Map-free visual relocalization: Metric pose relative to a single image. In: ECCV (2022) 1, 2, 4, 8
4. Balntas, V., Li, S., Prisacariu, V.A.: RelocNet: Continuous metric learning relo- calisation using neural nets. In: ECCV (2018) 4
5. Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-NeRF 360: Unbounded anti-aliased neural radiance fields. In: CVPR (2022) 1, 4, 10, 12
6. Beardsley, P.A., Zisserman, A., Murray, D.W.: Sequential updating of projective and affine structure from motion. IJCV (1997) 3
7. Bhat, S.F., Birkl, R., Wofk, D., Wonka, P., Müller, M.: ZoeDepth: Zero-shot transfer by combining relative and metric depth. arXiv (2023) 7, 9, 19
8. Bhowmick, B., Patra, S., Chatterjee, A., Govindu, V.M., Banerjee, S.: Divide and conquer: Efficient large-scale structure from motion using graph partitioning. In: ACCV (2015) 3
9. Bhowmick, B., Patra, S., Chatterjee, A., Govindu, V.M., Banerjee, S.: Divide and conquer: A hierarchical approach to large-scale structure-from-motion. CVIU (2017) 3
10. Bian, W., Wang, Z., Li, K., Bian, J.W., Prisacariu, V.A.: NoPe-NeRF: Optimising neural radiance field with no pose prior. In: CVPR (2023) 2, 4, 9, 11, 12, 20, 35
11. Brachmann, E., Cavallari, T., Prisacariu, V.A.: Accelerated coordinate encoding: Learning to relocalize in minutes using RGB and poses. In: CVPR (2023) 2, 3, 4, 6, 8, 9, 12, 14, 15, 16
12. Brachmann, E., Humenberger, M., Rother, C., Sattler, T.: On the limits of pseudo ground truth in visual camera re-localisation. In: ICCV (2021) 1, 11, 12, 17
13. Brachmann, E., Krull, A., Nowozin, S., Shotton, J., Michel, F., Gumhold, S., Rother, C.: DSAC-differentiable RANSAC for camera localization. In: CVPR (2017) 2, 4, 6
14. Brachmann, E., Rother, C.: Learning less is more-6D camera localization via 3D surface regression. In: CVPR (2018) 2, 4, 6
15. Brachmann, E., Rother, C.: Expert sample consensus applied to camera re- localization. In: ICCV (2019) 14
16. Brachmann, E., Rother, C.: Visual camera re-localization from RGB and RGB-D images using DSAC. IEEE TPAMI (2021) 2, 4, 6, 15
17. Brégier, R.: Deep regression on manifolds: a 3D rotation case study. In: 3DV (2021) 6
18. Brown, D.: The bundle adjustment-progress and prospect. In: Congr. of the Int. Soc. for Photogr. (1976) 3
19. Brown, M., Lowe, D.G.: Unsupervised 3D object recognition and reconstruction in unordered datasets. In: 3DIM (2005) 3
20. Carlone, L., Tron, R., Daniilidis, K., Dellaert, F.: Initialization techniques for 3D SLAM: A survey on rotation estimation and its use in pose graph optimization. In: ICRA (2015) 3
21. Cavallari, T., Bertinetto, L., Mukhoti, J., Torr, P.H., Golodetz, S.: Let’s take this online: Adapting scene coordinate regression network predictions for online RGB-D camera relocalisation. In: 3DV (2019) 2, 4, 6
22. Cavallari, T., Golodetz, S., Lord, N.A., Valentin, J., Di Stefano, L., Torr, P.H.: On-the-fly adaptation of regression forests for online camera relocalisation. In: CVPR (2017) 4, 6
23. Chen, S., Bhalgat, Y., Li, X., Bian, J., Li, K., Wang, Z., Prisacariu, V.A.: Neural refinement for absolute pose regression with feature synthesis. arXiv preprint arXiv:2303.10087 (2023) 4
24. Chen, S., Li, X., Wang, Z., Prisacariu, V.: DFNet: Enhance absolute pose regression with direct feature matching. In: ECCV (2022) 4
25. Chen, S., Wang, Z., Prisacariu, V.: Direct-PoseNet: Absolute pose regression with photometric consistency. In: 3DV (2021) 4
26. Cheng, Z., Esteves, C., Jampani, V., Kar, A., Maji, S., Makadia, A.: LU-NeRF: Scene and pose estimation by synchronizing local unposed NeRFs. In: ICCV (2023) 4
27. Crandall, D., Owens, A., Snavely, N., Huttenlocher, D.: Discrete-continuous op- timization for large-scale structure from motion. In: CVPR (2011) 3
28. Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scan- Net: Richly-annotated 3D reconstructions of indoor scenes. In: CVPR (2017) 8
29. Davison, A.J.: Real-time simultaneous localisation and mapping with a single camera. In: ICCV (2003) 3
30. DeTone, D., Malisiewicz, T., Rabinovich, A.: SuperPoint: Self-supervised interest point detection and description. In: CVPRW (2018) 4
31. Ding, M., Wang, Z., Sun, J., Shi, J., Luo, P.: CamNet: Coarse-to-fine retrieval for camera re-localization. In: ICCV (2019) 4
32. Dusmanu, M., Rocco, I., Pajdla, T., Pollefeys, M., Sivic, J., Torii, A., Sattler, T.: D2-net: A trainable CNN for joint description and detection of local features. In: CVPR (2019) 4
33. Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Comm. of the ACM (1981) 4, 6, 17
34. Gao, X.S., Hou, X.R., Tang, J., Cheng, H.F.: Complete solution classification for the perspective-three-point problem. IEEE TPAMI (2003) 4, 6
35. Gherardi, R., Farenzena, M., Fusiello, A.: Improving the efficiency of hierarchical structure-and-motion. In: CVPR (2010) 3
36. Govindu, V.M.: Combining two-view constraints for motion estimation. In: CVPR (2001) 3
37. Govindu, V.M.: Lie-algebraic averaging for globally consistent motion estimation. In: CVPR (2004) 3
38. Hartley, R., Trumpf, J., Dai, Y., Li, H.: Rotation averaging. IJCV (2013) 3
39. Hartley, R., Zisserman, A.: Multiple view geometry in computer vision. Cambridge University Press (2003) 3
40. Heinly, J., Schönberger, J.L., Dunn, E., Frahm, J.M.: Reconstructing the World in six days. In: CVPR (2015) 3
41. Humenberger, M., Cabon, Y., Pion, N., Weinzaepfel, P., Lee, D., Guérin, N., Sat- tler, T., Csurka, G.: Investigating the role of image retrieval for visual localization: An exhaustive benchmark. IJCV (2022) 4
42. Izadi, S., Kim, D., Hilliges, O., Molyneaux, D., Newcombe, R., Kohli, P., Shotton, J., Hodges, S., Freeman, D., Davison, A.J., Fitzgibbon, A.: KinectFusion: real-time 3D reconstruction and interaction using a moving depth camera. In: UIST (2011) 11
43. Jeong, Y., Ahn, S., Choy, C., Anandkumar, A., Cho, M., Park, J.: Self-calibrating neural radiance fields. In: ICCV (2021) 2, 4
44. Jin, Y., Mishkin, D., Mishchuk, A., Matas, J., Fua, P., Yi, K.M., Trulls, E.: Image matching across wide baselines: From paper to practice. IJCV (2021) 1
45. Kabsch, W.: A solution for the best rotation to relate two sets of vectors. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography 32(5), 922–923 (1976) 17
46. Kendall, A., Grimes, M., Cipolla, R.: PoseNet: A convolutional network for real- time 6-DoF camera relocalization. In: ICCV (2015) 2, 4
47. Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3D gaussian splatting for real-time radiance field rendering. ACM TOG (2023) 4
48. Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and Temples: Benchmark- ing large-scale scene reconstruction. ACM TOG (2017) 10, 13
49. Kraus, K.: Photogrammetry. No. v. 1 in Photogrammetry, Ferdinand Dummlers Verlag (1993) 3
50. Laskar, Z., Melekhov, I., Kalia, S., Kannala, J.: Camera relocalization by com- puting pairwise relative poses using convolutional neural network. In: ICCVW (2017) 4
51. Li, X., Wang, S., Zhao, Y., Verbeek, J., Kannala, J.: Hierarchical scene coordinate classification and regression for visual localization. In: CVPR (2020) 4, 6
52. Lin, A., Zhang, J.Y., Ramanan, D., Tulsiani, S.: Relpose++: Recovering 6d poses from sparse-view observations. In: 3DV (2024) 2, 4
53. Lin, C.H., Ma, W.C., Torralba, A., Lucey, S.: BARF: Bundle-adjusting neural radiance fields. In: ICCV (2021) 2, 4, 9, 11, 12, 20, 35
54. Lin, Y., Müller, T., Tremblay, J., Wen, B., Tyree, S., Evans, A., Vela, P.A., Birch- field, S.: Parallel inversion of neural radiance fields for robust pose estimation. In: ICRA (2023) 4
55. Lindenberger, P., Sarlin, P.E., Pollefeys, M.: LightGlue: Local feature matching at light speed. arXiv (2023) 4
56. Liu, C., Kim, K., Gu, J., Furukawa, Y., Kautz, J.: PlaneRCNN: 3D plane detection and reconstruction from a single image. In: CVPR (2019) 19
57. Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019) 7, 15
58. Lowe, D.G.: Distinctive image features from scale-invariant keypoints. IJCV (2004) 3, 4
59. Martinec, D., Pajdla, T.: Robust rotation and translation estimation in multiview reconstruction. In: CVPR (2007) 3
60. Meng, Q., Chen, A., Luo, H., Wu, M., Su, H., Xu, L., He, X., Yu, J.: GNeRF: GAN-based Neural Radiance Field without Posed Camera. In: ICCV (2021) 2
61. Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020) 1, 4
62. Moreau, A., Piasco, N., Bennehar, M., Tsishkou, D., Stanciulescu, B., de La Fortelle, A.: CROSSFIRE: Camera relocalization on self-supervised features from an implicit representation. ICCV (2023) 4
63. Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM TOG (2022) 4
64. Newcombe, R., Izadi, S., Hilliges, O., Molyneaux, D., Kim, D., Davison, A.J., Kohi, P., Shotton, J., Hodges, S., Fitzgibbon, A.: KinectFusion: Real-time dense surface mapping and tracking. In: ISMAR (2011) 11
65. Nistér, D., Naroditsky, O., Bergen, J.: Visual odometry. In: CVPR (2004) 3
66. NVIDIA![]() : NVIDIA V100 TENSOR CORE GPU. https://www.nvidia.com/en- us/data-center/tesla-v100/ (2017), [acessed March/14/2024] 32, 37, 38
: NVIDIA V100 TENSOR CORE GPU. https://www.nvidia.com/en- us/data-center/tesla-v100/ (2017), [acessed March/14/2024] 32, 37, 38
67. NVIDIA![]() : NVIDIA T4. https://www.nvidia.com/en-us/data-center/tesla- t4/ (2018), [acessed March/14/2024] 33
: NVIDIA T4. https://www.nvidia.com/en-us/data-center/tesla- t4/ (2018), [acessed March/14/2024] 33
68. Pollefeys, M., Koch, R., Vergauwen, M., Van Gool, L.: Automated reconstruction of 3D scenes from sequences of images. J. of Photogr. and Rem. Sens. (2000) 3
69. Rau, A., Garcia-Hernando, G., Stoyanov, D., Brostow, G.J., Turmukhambetov, D.: Predicting visual overlap of images through interpretable non-metric box embeddings. In: ECCV (2020) 4
70. Reality, C.: Reality Capture. https : / / www . capturingreality . com / realitycapture (2016), [accessed 15-Nov-2023] 1, 9
71. Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3D: Large-scale learning and evaluation of real-life 3D category reconstruction. In: ICCV (2021) 1
72. Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: CVPR (2019) 2, 4
73. Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: SuperGlue: Learning feature matching with graph neural networks. In: CVPR (2020) 4
74. Sarlin, P.E., Unagar, A., Larsson, M., Germain, H., Toft, C., Larsson, V., Polle- feys, M., Lepetit, V., Hammarstrand, L., Kahl, F., Sattler, T.: Back to the feature: Learning robust camera localization from pixels to pose. In: CVPR (2021) 4
75. Sattler, T., Leibe, B., Kobbelt, L.: Fast image-based localization using direct 2D- to-3D matching. In: ICCV (2011) 4
76. Sattler, T., Leibe, B., Kobbelt, L.: Improving image-based localization by active correspondence search. In: ECCV (2012) 2, 4
77. Sattler, T., Leibe, B., Kobbelt, L.: Efficient & effective prioritized matching for large-scale image-based localization. IEEE TPAMI (2016) 2, 4
78. Sattler, T., Torii, A., Sivic, J., Pollefeys, M., Taira, H., Okutomi, M., Pajdla, T.: Are large-scale 3D models really necessary for accurate visual localization? In: CVPR (2017) 2, 4
79. Sattler, T., Zhou, Q., Pollefeys, M., Leal-Taixe, L.: Understanding the limitations of CNN-based absolute camera pose regression. In: CVPR (2019) 4
80. Schaffalitzky, F., Zisserman, A.: Multi-view matching for unordered image sets, or “How do i organize my holiday snaps?”. In: ECCV (2002) 3
81. Schönberger, J.L.: Colmap Github Issues. https://github.com/colmap/colmap/ issues/116#issuecomment-298926277 (2017), [accessed Nov/15/2023] 9, 28, 37, 38
82. Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016) 1, 3
83. Shotton, J., Glocker, B., Zach, C., Izadi, S., Criminisi, A., Fitzgibbon, A.: Scene coordinate regression forests for camera relocalization in RGB-D images. In: CVPR (2013) 2, 4, 5, 6, 10, 11
84. Sinha, S., Zhang, J.Y., Tagliasacchi, A., Gilitschenski, I., Lindell, D.B.: Sparse- Pose: Sparse-view camera pose regression and refinement. In: CVPR (2023) 2, 4
85. Smith, L.N., Topin, N.: Super-convergence: Very fast training of neural networks using large learning rates. In: Arti. Intell. and Mach. Learn. for Multi-Domain Operations Appli. (2019) 9
86. Snavely, N., Seitz, S.M., Szeliski, R.: Photo tourism: exploring photo collections in 3D. ACM TOG (2006) 3
87. Snavely, N., Seitz, S.M., Szeliski, R.: Modeling the world from internet photo collections. IJCV (2008) 3
88. Snavely, N., Seitz, S.M., Szeliski, R.: Skeletal graphs for efficient structure from motion. In: CVPR (2008) 3
89. Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: LoFTR: Detector-free local feature matching with transformers. In: CVPR (2021) 4
90. Szeliski, R., Kang, S.B.: Recovering 3D shape and motion from image streams using nonlinear least squares. J. of Vis. Com. and Image Repr. (1994) 3
91. Tancik, M., Weber, E., Ng, E., Li, R., Yi, B., Kerr, J., Wang, T., Kristoffersen, A., Austin, J., Salahi, K., Ahuja, A., McAllister, D., Kanazawa, A.: Nerfstudio: A modular framework for neural radiance field development. In: ACM TOG (2023) 2, 10, 11, 13, 16, 20, 34, 35
92. Teed, Z., Deng, J.: DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. In: NeurIPS (2021) 9, 11, 12, 13, 20, 34, 35
93. Toldo, R., Gherardi, R., Farenzena, M., Fusiello, A.: Hierarchical structure-and- motion recovery from uncalibrated images. CVIU (2015) 3
94. Triggs, B., McLauchlan, P.F., Hartley, R.I., Fitzgibbon, A.W.: Bundle adjust- ment—a modern synthesis. In: Int. Worksh. on Vis. Alg. (2000) 3
95. Türkoğlu, M.Ö., Brachmann, E., Schindler, K., Brostow, G., Monszpart, A.: Vi- sual camera re-localization using graph neural networks and relative pose supervision. In: 3DV (2021) 4
96. Ulyanov, D., Vedaldi, A., Lempitsky, V.: Deep image prior. In: CVPR (2018) 7
97. Ummenhofer, B., Zhou, H., Uhrig, J., Mayer, N., Ilg, E., Dosovitskiy, A., Brox, T.: DeMoN: Depth and motion network for learning monocular stereo. In: CVPR (2017) 2
98. Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geometric 3D vision made easy. In: CVPR (2024) 2, 4, 9, 11, 12, 20
99. Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP (2004) 19, 20, 33, 34, 35
100. Wang, Z., Wu, S., Xie, W., Chen, M., Prisacariu, V.A.: NeRF--: Neural radiance fields without known camera parameters. arXiv (2021) 2, 4, 7
101. Wei, X., Zhang, Y., Li, Z., Fu, Y., Xue, X.: DeepSFM: Structure from motion via deep bundle adjustment. In: ECCV (2020) 2
102. Wu, C.: Towards linear-time incremental structure from motion. In: 3DV (2013) 3
103. Xia, Y., Tang, H., Timofte, R., Van Gool, L.: SiNeRF: Sinusoidal neural radiance fields for joint pose estimation and scene reconstruction. In: BMVC (2022) 2, 4
104. Yen-Chen, L., Florence, P., Barron, J.T., Rodriguez, A., Isola, P., Lin, T.Y.: iNeRF: Inverting neural radiance fields for pose estimation. In: IROS (2021) 4, 7
105. Zhang, J.Y., Lin, A., Kumar, M., Yang, T.H., Ramanan, D., Tulsiani, S.: Cameras as rays: Pose estimation via ray diffusion. In: ICLR (2024) 2, 4
106. Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018) 19, 20, 33, 35
107. Zhang, W., Kosecka, J.: Image based localization in urban environments. In: 3DPVT (2006) 4
108. Zhou, Q., Sattler, T., Pollefeys, M., Leal-Taixe, L.: To learn or not to learn: Visual localization from essential matrices. In: ICRA (2020) 4